
Spring新版本的响应式编程
流式编程在微服务架构风格越来越流行的背景下日益引起开发者的关注 (前文有一些简单探讨) ,新的Java语言规范加入了流的概念从语言库上添加了对FRP的支持。 Spring最新的5.0版本更新也顺应这一潮流,加入了原生支持FRP的行列。
最大的版本改动源于设计范式选择的增加
Spring的官方博客声称该版本的改动是项目从2014年创立以来最大的一次版本更新;主要的考虑是, 增加对异步流式编程范式的支持在Java语言平台下是一个思维方式上的巨大变化。
传统的Java编程范式是基于面向对象设计的实现,具体到底层上还是命令式的同步、阻塞调用思维; 你调用一个对象提供的方法,则调用者默认必须等待操作完毕之后,用返回值(或者异常)的方式通知调用者。 即使有异步编程技术的辅助,这些细节也被认为是抽象接口下面的实现细节,很少被作为主要的设计决策。 FRP的方式就显著地不同,它的主要设计对象变为异步的流,所以对流的操作、变换等都是异步发生的, 程序的主要逻辑不需要再关注底层的操作是怎么被调度的,而仅仅关心一个一个具体的操作应该做什么,互相配合完成系统目标。 这个角度来说,FRP的方式是声明式的;而声明式的代码相对传统的过程式代码有更好的可读性和可维护性。
经典的面向对象设计方法容易入门却不易精通,设计者很容易掉入过度设计的陷进而滥用继承(接口也是类似)而带来不必要的过度抽象; 当然抽象不足也是另外一个问题这里略去不提。GoF在设计模式里面特别声明了我们需要考虑优先使用组合而不是继承, 不幸的是这一忠告从来就没有被人们认真对待;生搬硬套这些模式的设计者很容易就掉入叠床架屋的花花架子中无法自拔。 FRP的思维方式完全不提继承的事儿,但是封装依然是必要的;组合则被提到了首要的位置,因为函数式编程的主要复用方式就是组合。
Spring其实采用了一种相对中庸的态度,给你提供了FRP的支持,但是决定权仍然在用户自己手里; 你可以选择用传统的OOD方式,这样更熟悉也没有什么额外的迁移成本;也可以根据项目的实际情况, 选用异步的函数式编程,当你决定这样选择的时候,Spring的基础设施已经做到足够的完善,你可以仅仅关注于你的程序逻辑就行了。
和其他JVM上的FRP的对比
如果将视角扩大到整个JVM平台上,那么Spring显然不是唯一的选择,也不是最强大的FRP选择。 类似于Akka这样的框架本身就是基于Actor模型来实现更高层次的函数式编程设施的,尽管Actor的模型和FRP并不是完全目标一致。 Scala语言则提供完整的函数式编程语言支持,更复杂的FP抽象也不在话下,在Java8之前甚至被认为是JVM平台下最好的选择。 RxJava以语言扩展的方式也出现了比较长的时间。
Spring 5.0的核心FRP抽象逻辑和上述这些高层的框架的核心概念是一致的;它独特的地方在于其本身作为一个开源平台的灵活性; 你可以选择用Spring Boot,也可以不用;可以选择微服务架构来使用FRP,也可以完全不使用微服务架构。 正如Netflix在其Zuul2项目的重构过程中所总结的,尽管使用异步的方式来构建程序可以极大地提高性能和资源使用的有效性,提高自动扩展的能力; 运维的难度和调试挑战也被急剧放大。如果用来解决正确的问题,收效就会比较大,然而如果用来解决错误的问题,情况反而会更加糟糕。 关键的是,我们需要用正确的工具来解决正确的问题。
SpringMVC和WebFlux
Spring-webmvc是Spring中的一个经典MVC模块,它最初是作为一种基于Servelet技术的Web后端框架提供给后端程序员使用的。传统的Spring MVC框架工作机制如下
DispatcherServelet会搜索WebApplicationContext来查找DI容器中注册的Controller以处理进来的HTTP请求- 本地化解析的Bean在这一过程中也会被一并查找并关联起来以便后续渲染View的时候使用来本地化View中的显示内容
- 主题解析的Bean则被用来关联后续要使用的View模板,以进行CSS渲染等额外处理
- 如果HTTP请求包含多部分媒体内容,那么请求会被封装在一个
MultipartHttpServeletRequest中处理 - Dispatcher会搜索对应的Handler,找到之后,handler对应的controller以及其前置处理、后续处理会被按照顺序依次处理以准备模型返回,或者被用于后续View渲染
- 如果一个模型被返回,对应的View就会被渲染并返回响应的HTTP消息 整体的处理逻辑是一个线性的同步处理逻辑。
传统的Sping MVC框架的接口都定义在 org.springframework.web.servlet包中,而支持响应式编程的Web框架被命名为WebFlux,对应的接口和注解放在一个新的Java包中:
org.springframework.web.reactive。它是全异步、非阻塞的,可以很方便的使用在基于事件循环的异步编程模型中,仅仅需要很少个线程就可以高效地处理大量的请求。
其功能不仅支持传统的Servelet容器,也支持诸如Netty、Undertow这些不是基于Servelet的编程框架上。
Mono和Flux
Mono或者Flux对象概念有些类似于Java8中的CompletableFuture,自身支持类似的lambda表达式组合来实现流式操作。
这两个类型本质上实现了Reactive Stream中的Publish的概念,可以认为它是流的发布者。
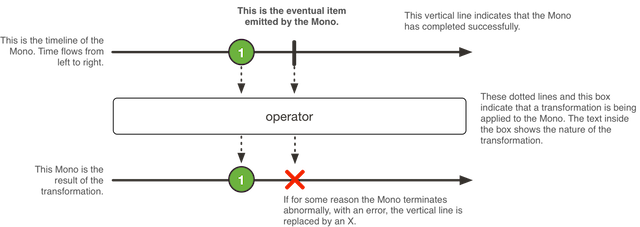
Mono用来表示可以最多产生一个结果或者产生一个错误的流发布者概念。
改类型提供了丰富的构造方法来产生Mono对象,我们可以通过
just方法就地构造出一个会产生传入类型对象的值的封装对象justOrEmpty方法可以从一个Optional对象中获取值作为发布的对象,如果里面没有值则不产生实际的事件fromXXX方法从各种各样的事件源中获取一个对象,譬如一个CompletableFuture对象,或者Supplier函数对象,或者线程执行结果,乃至另外一个Publisher接口的实现对象等never则用于模拟永远不会终止的事件,下游的流订阅者永远不会得到通知- 组合多个发布者对象的聚合操作,如
when用于在给定的多个发布者中任何一个产生事件的时候,其结果时间被作为单一的输出事件的情况;first用于等待传入的多个发布者中的第一个发布者产生输出事件的时候,将其作为整体的输出事件,更高级的zipXXX方法则支持更复杂的语义 and方法则用于合并本身和传入的Mono中的事件,在两者都结束的时候,产生一个空的事件作为输出
zip本身支持多种不同的语法,一种是带转换函数的方法,声明为 zip(Iterable<? extends Mono<?>> monos, Function<? super Object[],? extends R> combinator),
作用机制是,对传入的多个事件发布者,当他们的事件结果都被产生的时候,调用传入的聚合函数,对这些事件的结果进行函数运算,并将其返回值作为最终的事件输出。
另一种用法是将结果返回为元组而不做额外的运算;因为Java本身不支持不同类型的变长模板参数,对应的声明需要对不同的参数个数单独写出来,最多可以支持6个事件的元组组合,即
static <T1,T2,T3,T4,T5,T6> Mono<Tuple6<T1,T2,T3,T4,T5,T6>>
zip(Mono<? extends T1> p1, Mono<? extends T2> p2, Mono<? extends T3> p3, Mono<? extends T4> p4, Mono<? extends T5> p5, Mono<? extends T6> p6)
Flux和Mono的不同是,它本身会产生0到N个事件输出到流中;然后才最终完成或者报错。
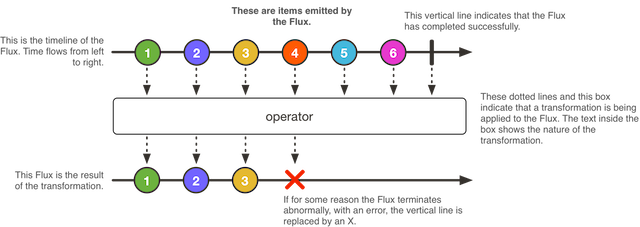
由于Flux本身就会产生多个事件,多个Flux之间的组合处理就会变得更加复杂和灵活;它本身支持如下一些API
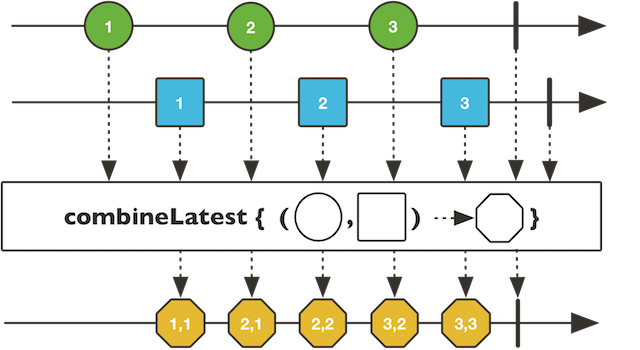
combineLatest会组合多个发布者中的最近发生的事件,依照事件顺序依次将其作为输出事件,最终产生的事件序列会按照时间交错concat方法会将多个发布者的事件一一串起来而不管各自发生的时间merge方法会将单一的事件发布者的事件交叉串成一个新的Flux发布出来zip的逻辑和Mono类似,只是这里的合并函数需要处理多个Tuple对象
如combineLatest的事件发布逻辑如下
WebClient
传统的Spring MVC中,我们可以使用RestTemplate来组装发起HTTP客户端请求,对应的Reactive版本的概念是WebClient。
一个最简单的异步发起HTTP请求的例子如下
WebClient webClient = WebClient.create();
Mono<Person> person = webClient.get()
.uri("http://localhost:8080/persons/42")
.accept(MediaType.APPLICATION_JSON)
.exchange()
.then(response -> response.bodyToMono(Person.class));
这里例子依然是使用WebClient俩创建一个流。WebClient提供了丰富的API来操纵HTTP客户端行为;
默认情况下HTTP的连接通过Netty来完成,有需要的情况下,用户也可以自己指定一个ClientHttpConnector用插件的方式配置进来。
WebClient的API提供了fluent风格的链式调用,并在需要输出的情况下返回一个Mono或者Flux对象。
exchange()方法无法处理服务端返回的非2XX响应,如果需要处理,可以使用retrieve()方法来做,譬如
Mono<Person> result = client.get()
.uri("/persons/{id}", id).accept(MediaType.APPLICATION_JSON)
.retrieve()
.onStatus(HttpStatus::is4xxServerError, response -> ...)
.onStatus(HttpStatus::is5xxServerError, response -> ...)
.bodyToMono(Person.class);
上述的onStatus方法的第二个参数可以用lambda表达式书写,以得到更好的可读性。
封装HTTP的Body
如果不需要关心操作的返回,我们也可以用Void类型来填充流发布者(Mono/Flux)的模板参数。同时在POST方法中,
我们往往需要填充具体的HTTP请求的消息体,它往往也是用JSON的格式来发送给服务器端的;实现的方法是,可以直接将一个对象填进去即可。
如下面的创建一个REST资源的例子
Flux<Person> personFlux = createSomePerson();
Mono<Void> result = client.post()
.uri("/person/{id}", id)
.contentType(MediaType.APPLICATION_STREAM_JSON)
.body(personFlux, Person.class)
.retrieve()
.bodyToMono(Void.class);
如果对应的资源对象可以直接得到而不需要通过流异步获取,那么可以直接调用syncBody
Person person = constructPerson();
Mono<Void> result = client.post()
.uri("/persons/{id}", id)
.contentType(MediaType.APPLICATION_JSON)
.syncBody(person)
.retrieve()
.bodyToMono(Void.class);
服务端的支持
服务端的支持有两个层,一个是用于处理HTTP方法请求的HttpHandler,一个是WebHandler。
HttpHandler 在Web服务器启动的时候,需要和对应的服务地址和端口相绑定;不同的服务实现都需要和业务代码自己写的HttpHandler绑定起来组合使用。 Spring的闪亮指出一方面在于其高度的灵活性,不同的第三方Web Server实现都可以通过几行代码绑定使用起来。 比如使用Netty的方式如下
HttpHandler handler = ...
ReactorHttpHandlerAdapter adapter = new ReactorHttpHandlerAdapter(handler);
HttpServer.create(host, port).newHandler(adapter).block();
另外一个流行的Web框架Jetty的使用方法如下
HttpHandler handler = ...
Servlet servlet = new JettyHttpHandlerAdapter(handler);
Server server = new Server();
ServletContextHandler contextHandler = new ServletContextHandler(server, "");
contextHandler.addServlet(new ServletHolder(servlet), "/");
contextHandler.start();
ServerConnector connector = new ServerConnector(server);
connector.setHost(host);
connector.setPort(port);
server.addConnector(connector);
server.start();
基于HttpHandler, WebHandler提供了更高层次的处理链,包括诸如异常处理,过滤器,以及目标的WebHandler。所有的组件都是在ServerWebExchange之上工作的,
所有这些处理链都可以用一个WebHttpHandlerBuilder来组装,最终组装的结果是一个上述的HttpHandler,并最终运行在不同的WebServer实现上。
DispatcherHandler
和SpringMVC的基本概念一样,居于中心地位的是一个DispatcherHandler,它本身是一个Bean,可以被Spring的DI容器框架自动发现并加入到上述的WebHttpHandlerBUilder中,
载入服务器实现中最终提供对外服务。DispatcherHandler的Bean名字被设置为webHandler,并实现了ApplicationContextAware接口,以便它可以访问DI容器上下文。
DispatcherHandler是通过委托给一些实现定义的Spring的Bean来完成对HTTP请求的处理,并渲染对应的HTTP响应消息的。
Spring-WebFlux框架提供了默认的实现以保证这些Bean是开箱即用的,同时用户也可以根据需要来扩展、定制这些组件。
这些Bean包括
- HandlerMapping 负责经对应的请求派发给某个Handler实现
- HandlerAdapter帮助
Dispatcher依据注解解析等手段将Handler调用的细节和DispatcherHandler的逻辑解耦 - HandlerResultHnaler用于处理上一个
HandlerAdapter返回的结果
DispatcherHandler的处理流程如下
- 查询所有的
HandlerMapping,并选择第一个匹配的Handler - 如果找到,则使用对应的
HandlerAdapter来触发Handler调用,它会发挥一个HandlerResult - 上述的Result会被
HandlerResultHandler所处理以便产生Response并将Response送给View层去渲染,或者直接返回给客户端
Controller
传统的Spring MVC框架下应用程序仅仅需要按照业务逻辑划分,分别写好Controller,并用注解来指明某个方法需要处理的方法,带入请求作为参数,即可指定自己的参数校验Bean, Spring框架会自动帮我们完成参数校验到请求分发这一系列背后的复杂处理。这些已有的注解在Reactive方式下仍然被完美地支持。
传统的这些注解都继续被用同样的方式所支持
@RestController标注一个POJO是一个controller类@PostMapping/@PutMapping/@GetMapping...可以加注在方法上,Spring可以自动发现他们用来处理对应的Web方法请求,注解中的参数可以用于携带URL等@ResponseStatus可以用来指定HTTP返回的状态码@PathVariable可以用于将URL中的参数传入进来绑定到Java类型的参数上,甚至正则表达式也可以被处理- 媒体类型的注解也可以放置在方法注解的参数中 这些注解的用法和意图都和传统的Sping MVC没什么两样,这里无需赘述。
函数式的端点
Spring WebFlux提供了新的基于函数变换的Web处理端点,它的基本逻辑是基于函数式的不可变设计的。虽然和上述传统的基于注解的方式看起来有很多差异, 两者却是可以完美地运行在同样的底层服务实现上的。
和HandlerFunction相对应的处理HTTP请求的handler函数通常接收一个HTTP请求作为输入,并产生一个Mono<ServerResponse>作为处理的输出。这样的一个函数
作用上和一个声明了@RequestMapping的方法类似,不同的是ServerRequest和ServerResponse都被设计为是符合不可变对象的约束。
访问一个请求中的内容的方法通过bodyToXXX的方式来实现,比如
Mono<String> string = request.bodyToMono(String.class);
就可以返回一个将会产生一个字符串作为输出事件的发布者。
类似地,我们也可以使用bodyToFlux返回一个Flux的封装,两者在底层上都是通过一个更灵活的body(BodyExtractor)方法来实现的。
bodyToMono其实等价于body(BodyExtractors.toMono(String.class)。
如果需要叠加对响应消息的额外处理,使用流的方式则可以用一个Builder对象来完成,因为ServerResponse本身是不可变的。
用lambda表达式的方式写一个简单的Hello程序,可以是
HandlerFunction<ServerResponse> helloWorld =
request -> ServerResponse.ok().body(fromObject("Hello World"));
当然这样的书写方式有潜在的可读性丢失的损耗。另外一种推荐的做法是,将不同的handler仍然聚合到一个controller类中,然后用不同的方法来组合实现不同的处理, 下面是一个更复杂的例子
public class PersonHandler {
private final PersonRepository repository;
public PersonHandler(PersonRepository repository) {
this.repository = repository;
}
public Mono<ServerResponse> listPeople(ServerRequest request) {
Flux<Person> people = repository.allPeople();
return ServerResponse.ok().contentType(APPLICATION_JSON).body(people, Person.class);
}
public Mono<ServerResponse> createPerson(ServerRequest request) {
Mono<Person> person = request.bodyToMono(Person.class);
return ServerResponse.ok().build(repository.savePerson(person));
}
public Mono<ServerResponse> getPerson(ServerRequest request) {
int personId = Integer.valueOf(request.pathVariable("id"));
Mono<ServerResponse> notFound = ServerResponse.notFound().build();
Mono<Person> personMono = this.repository.getPerson(personId);
return personMono
.flatMap(person -> ServerResponse.ok().contentType(APPLICATION_JSON).body(fromObject(person)))
.switchIfEmpty(notFound);
}
}
路由处理函数
通常情况下,我们不需要自己写路由函数,仅仅需要调用RouterFunctions.route(RequestPredicate, HandlerFunction)做分发就可以了。
如果第一个参数指定的谓词判断匹配进来的HTTP请求,那么第二个参数指定的HandlerFunction就会被调用,并将请求传入,正如上面例子中一个一个的public方法所做的那样。
如果没有找到匹配的,则直接返回404(即上例中的notFound)。
多个路由函数可以通过函数式编程的组合方法构造出新的路由函数来。匹配的时候,先比对第一个函数,如果没有匹配再一次往下顺序比对和处理。
我们可以使用RouterFunction.and(routeFunction)或者or来组合多个条件判断,用andRoute来组合多个路由函数,写出的代码是比较清晰易懂的流畅风格。
基于上面的例子,使用路由函数的组合如下
PersonRepository repository = ...
PersonHandler handler = new PersonHandler(repository);
RouterFunction<ServerResponse> personRoute =
route(GET("/person/{id}").and(accept(APPLICATION_JSON)), handler::getPerson)
.andRoute(GET("/person").and(accept(APPLICATION_JSON)), handler::listPeople)
.andRoute(POST("/person").and(contentType(APPLICATION_JSON)), handler::createPerson);
每一行一个路由函数的方式具有很强的不言自明性,不需要稳定仅仅通过读这段代码就可以知道每个URL是怎样被某个函数所处理了。
由于这里的主要编程范式是函数式的,Spring库提供的大部分组合函数都是静态函数,这里的方法引用逻辑借助于Java8的语法特性进一步提高了lambda表达式的表达能力。 这也许是这些新特性都仅仅在Java8平台下才能工作的原因。
启动Server和过滤器
启动一个后端Web服务器的方法和前面的类似,只是我们需要构造一个HttpHandler出来;实现的方法是通过RouterFunctions.toHttpHandler(routerFunction);
构造出来的HttpHandler就可以被用相同的方法调用特定的后端服务器实现了。
过滤器可以用在routerFunction组合之间,提供额外的安全控制和拦截器处理。譬如如下的使用SecurityManager的例子
RouterFunction<ServerResponse> filteredRoute =
route.filter(request, next) -> {
if (securityManager.allowAccessTo(request.path())) {
return next.handle(request);
}
else {
return ServerResponse.status(UNAUTHORIZED).build();
}
});
当给定的请求可以被安全策略放行的时候,我们可以直接调用next.handle(request)将其交给下游,否则直接构造一个授权错误的响应,结束该请求的处理流程。
Leave a Comment
Your email address will not be published. Required fields are marked *