
函数式反应式编程
流式编程或者响应式编程则是一个不断进入我们视线的设计概念;它采用声明式编程范式,并将数据流和数据更新的处理作为程序运算的核心。 由于函数式编程本身即强调声明式编程,这使得用函数式编程的语言或者工具来实现响应式编程更自然清晰, 一般人们将二者的结合称为函数式反应式编程或者FRP。 FRP最早可以追溯到微软和耶鲁的两位先驱在97年发表的论文,
基本概念
从基本思想上看,FRP本质上是以函数式编程思想为基础的。
函数式编程的简单历史
函数式编程早不是一个新鲜的概念,在计算机历史的早期阶段就被提出和实现, 可能是由于它和数学理论概念更接近,即使是有Haskell这样的致力于提升影响力的开源项目在上个世纪八十年代被提出以解决不同的语言语义分裂的问题, 也长期不能带其脱离“叫好不叫座”的尴尬境地,毕竟Unix/C的影响力太大了,以至于大部分人更喜欢面向过程的具体化思维,即使是一度流行的面向对象技术 也得和传统的面向过程技术相结合才取得了长足的发展。
进入21世纪以来,传统的依赖单核CPU频率提升的“摩尔定律”慢慢失效,软件的复杂性又与日俱增对计算能力的需求有增无减, 原本用于大型机的多处理器核心被引入以应对商业软件领域的挑战。不幸的是传统的面向对象技术并不能很好地应对这些挑战; 自然而然可以优雅地应对这些挑战的函数式编程技术重新引起人们的关注。
微服务架构的兴起则为两者的结合提供了更好的舞台,因为无状态是微服务的潜在要求也是最重要的一个要求之一; 函数式编程相较于其他编程范式更强调无副作用的编程思维,和微服务的基本要求自然契合的很好。
函数式编程的基本概念
函数式编程的基本思路是将程序的执行看作是一堆函数的组合处理和求值过程;纯粹的函数式编程要求数据是不可变的, 同样的数值输入在流经同样的函数处理的时候必须得到确定的输出,不容许有预料之外的副作用产生。程序员的任务可以想象为两个过程
- 声明运算过程所需要的函数及其组合算法;程序的主要逻辑是组合这些函数算法来完成运算
- 实现这些函数的内部逻辑实现,这个过程内部仍然是以声明式的写法为主
由于声明式的代码更接近于实际的问题领域逻辑,一个明显的好处是函数式代码具有很高的可读性和可维护性。
流及反应式抽象
流的抽象在计算机编程语言和计算机基础技术中非常常见。
C++语言的早期STL标准库就提出了IO流的概念,它将输入输出设备进行抽象, 外部用户仅仅需要关心自己的数据可以写入流中或者从流中读取,具体怎么实现底层的输入输出控制的细节则被标准IO流库所封装和隐藏。
TCP协议的设计是另外一个例子,逻辑上看TCP服务的提供者和使用者之间在通信之前需要先建立一个虚拟的数据流, 然后发送方可以按照严格而固定的顺序将数据写入这个数据流中,对方则可以保证按照发送发的写入顺序读取到数据。 这里一个明显的共同特征是,流用于表述一种允许生产者顺序往后追加,消费者可以依据同样顺序读取出数据的逻辑抽象通道。 只要逻辑通道处于连接状态,发送方就可以持续不断地向数据流中填充数据,接收方则可以得到保证不管中间经过多少节点(路由器或者交换机), 数据总是以相同的顺序被放置在本地的协议栈缓冲中以便读取(这里暂不考虑网卡驱动丢包等异常情况)。
Unix 的管道也满足类似的特征,管道的输入端进程可以源源不断地将自己的标准输出信息重定向到给定的管道中, 而管道另外一侧的进程则按照同样的顺序从管道里读取数据。
这些例子中,流中的数据是一经产生即不会被修改的,并且多个不同的流其实可以或多或少按照某种方式去组合;譬如可以组合多个进程, 让前一个进程的输出作为下一个进程的收入,管道的长度可以达到任意长度(当然实际的长度会受制于计算机的处理能力 )。 同时这种采用组合来扩展程序的能力虽然简单却有着巨大的威力,管道的思想被认为是 Unix 编程哲学的核心要义之一。
在这种抽象语义下,除了流的开端出的处理逻辑,其它相连的中间处理过程或者结束过程都是反应式的,即遵循被动式的处理逻辑: 从输入中拿到内容 (可以是消息或者应用数据 ) , 按照业务领域意图做转换处理,然后将产生的结果放入流中,以便下游可以继续处理。
将两者相结合
上述流的抽象其实和函数式编程的基本要素可以无缝地融合在一起,因为流的运算特征满足不可变性的特征,并且易于组合。
简单地说,FRP的核心思维方式是将异步的数据流作为基本的数据抽象,异步是为了解耦处理流的处理和参与者; 作为编程模型的基本抽象,它支持用各种各样的方式来创建数据流,可以是一个外部的变量,也可以是图形界面点击事件, 缓冲更新等等。
基于该基本抽象,FRP还提供给使用者灵活的工具箱来处理流,使我们可以创建新的流、过滤已有的流、组合或者终结流的数据; 显然这些操作手法是典型的函数式的,所不同的是流被当作了基本的数据处理单元, 上述的这些操作都可以看作是作用于流的函数或者高阶函数。
FRP的实现基本都依赖于基本的函数式编程特性,尽管各种编程语言不约而同地慢慢从函数式编程语言中汲取营养加入到新的版本中, 或者没有历史兼容包袱(适合于一些新语言)地直接在语言核心加入函数式编程支持,
在不同的编程语言中实现FRP面临的挑战也是不一样的。最有名的FRP实现是 ReactiveX, 下面我们来粗略看下不同的编程语言中的RFP实现和基本特征。
Javascript
Javascript从早期版本开始就支持函数作为语言基本设施这一重要的函数式编程入门条件,在Javascript中实现FRP也比较清晰容易。
想象一个简单的功能:我们需要在启动的时候从github中读取三个账户数据,用过程式的方法也很简单, 但是我们这里想用FRP的方法来实现并顺便看下它的基本语义。
首先我们需要先产生一个流,毕竟这是一切运算的基础,用ReactiveX 的说法我们需要一个 Observable,我们可以简单认为它就是一个流
var requestStream = Rx.Observable.just('https://api.github.com/users');
这时候我们得到的还仅仅是一个字符串流;我们需要给它加上一些动作,当对应的数据被推送给流的时候,后续的运算可以继续进行下去
requestStream.subscribe(function(requestUrl) {
// execute the request
var responseStream = Rx.Observable.create(function (observer) {
jQuery.getJSON(requestUrl)
.done(function(response) { observer.onNext(response); })
.fail(function(jqXHR, status, error) { observer.onError(error); })
.always(function() { observer.onCompleted(); });
});
responseStream.subscribe(function(response) {
// do something with the response
});
}
上述代码中,我们用 subscribe 函数作为组合函数,对应的参数是一个函数,该函数会取到 requestStream 中的字符串URL,
执行AJAX回调,并基于处理结果决定如何处理流,这里的 create 函数用于创建一个自定义的流,传入的 observer 为下游的stream (ReactiveX叫他Observable)。
当AJAX异步执行成功或者出错的时候,上面的实现将对应的相应结果通知给下游,分别是
onNext通知下一个数据需要被处理onError通知异常情况发生,遇到错误需要被处理onCompleted标记流的结束
需要处理这些响应数据的代码写在第二个 subscribe 代码块中。
上面的代码中,我们在一个流的处理中嵌套了另外一个流的处理,写的多了很容易掉入 Callback Hell 的陷阱。 所幸的是,我们可以使用流变换的技术来简化它,重写为如下的版本
var responseMetastream = requestStream
.map(function(requestUrl) {
return Rx.Observable.fromPromise(jQuery.getJSON(requestUrl));
});
这是函数式编程中基本的map函数 - 将一种数据经过运算后编程另外一种数据,这里麻烦的是我们的map默认就会将内部的返回类型封装为一个Stream,
加上里面的返回值本身已经是一个 Stream,最终我们得到了一个封装了两次的stream,好在flatMap可以帮我们轻松解开一层封装
var responseStream = requestStream
.flatMap(function(requestUrl) {
return Rx.Observable.fromPromise(jQuery.getJSON(requestUrl));
});
实现的流处理过程如下图
更复杂的功能可以参考这篇gist,文字和视频都很清晰易懂。
Java8 基本流
Java8在JDK中提供了丰富的 stream API,其定义是一个泛型的接口,支持最基本的流操作,包括 map/flatMap/filter/skip/sorted/reduce等方法。
一个新的stream对象可以用包括静态的of方法、Builder辅助类构造出来,同时JDK提供的Collection类大多支持一个新的stream()方法用以构造一个新的stream对象。
需要注意的是Java8语言本身的函数式支持是通过面向对象的方法来模拟的,只是从FRP编程的角度来看,可以认为Java8的流是用函数式思维组织设计,用OO的方法来提供实现。 更多Java8的函数式特性和流实现细节记录在这篇文章中。
RxJava扩展
RxJava 项目用库的方式对JVM平台进行扩展,提供易于组合、异步、事件驱动的反应式编程支持。 它的基本思路是扩展观察者模式 以方便地支持数据、事件流,并提供高层抽象, 将核心业务逻辑和底层的线程、同步、并发数据结构这些计算机底层的具体技术所隔离,使得应用程序开发者可以更关注于业务逻辑,提高开发效率。
由于反应式编程天然和函数式编程的关系密切,并且Java8才支持Lamba表达式和Stream这些抽象,所以在Java8平台上使用 RxJava 会更清晰自然。
一个最简单的回显 Hello World 的流程序的例子如下
import io.reactivex.*;
public class HelloWorld {
public static void main(String[] args) {
Flowable.just("Hello world").subscribe(System.out::println);
}
}
这个最简单的例子中, 我们先使用 Flowable.just 方法产生一个流并初始化为传入的数据 Hello World,并且当给定的数据传入流之后,流即终止。
subscribe方法则提供一个流数据的消费者,这里是一个lambda表达式,将实际数据传给 System.out.println 打印在控制台上。
当然这个例子是在实际应用中没多大意义,没有人会写出这样的实际代码来增加无畏的复杂性。
更复杂一点的例子
更常见一点的任务是,我们想根据输入数据做一些运算,这些运算本身可能比较复杂而耗时所以我们希望它在一些后台进程上做,做完之后,再将结果汇聚起来放在界面上显示出来。 如果我们采用Java7提供的并发包中的工具来做,则需要仔细考虑一下线程之类的东西 (或者使用ForkJoinPool来做); RxJava 则允许我们仅仅关注于需要解决的问题逻辑,其实现可以如下
Flowable.fromCallable(() -> {
Thread.sleep(1000); // imitate expensive computation
return "Done";
}).subscribeOn(Schedulers.io())
.observeOn(Schedulers.single())
.subscribe(System.out::println, Throwable::printStackTrace);
该例中,每一个语句调用结果都会产生一个新的不可变的 Flowable对象出来,整个代码的书写方式是链式调用的风格;如果将每个调用写在单独的一样上,
应用处理逻辑则一目了然。
RxJava并不直接使用Java8的线程或者 ExecutorService 接口,而是用 Scheduler 抽象和底层的JVM线程库做交互;Scheduler 负责和底层的线程或者
ExecutorService实例做绑定;遵循常用的Java命名约定,Schedulers 工具类封装了一些常用的静态 Scheduler 实例方便编程使用。
使用并发
RxJava 允许并发的运行计算以提高处理能力,然而当流中的输入数据是线性传入的时候,默认情况下则无法并发,下面的例子
Flowable.range(1, 10)
.observeOn(Schedulers.computation())
.map(v -> v * v)
.blockingSubscribe(System.out::println);
虽然使用了默认共享的计算线程池(假设我们有多个处理器核心),但是因为输入的数据是线性传入的,中间的计算并不会自动地派发到多个计算线程上。
为了打开并发处理,我们需要额外下一番功夫,使用 flatMap 方法显示地展开流并在运算完毕后自动合并流数据:
Flowable.range(1, 10)
.flatMap(v ->
Flowable.just(v)
.subscribeOn(Schedulers.computation())
.map(w -> w * w)
).blockingSubscribe(System.out::println);
新一点的版本中,RxJava还加入了 parallel() 方法以生成一个并发的流对象 ParallelFlowable 从而更大地简化代码
Flowable.range(1, 10)
.parallel()
.runOn(Schedulers.computation())
.map(v -> v * v)
.sequential()
.blockingSubscribe(System.out::println);
需要注意的是,Flowable 和 ParallelFlowable 是完全不同的类型,二者都是泛型类,但没有共同的接口。ParallelFlowable提供了丰富的接口可以得到一个Flowable
reduce可以用一个调用者指定的函数来得到一个顺序的流sequential可以显示地从每个流的尾部用轮询的方式得到一个顺序流sorted则可以排序并发流并合并的恶道一个顺序流toSortedList则得到一个排序列表的流
合理的设计和使用
RxJava 建议最好的使用方式是 :
- 创建产生数据的可被流感知的对象(
Observable),作为流的输入数据 - 创建对数据进行运算的处理逻辑,它们自己本身可以对流推送过来的数据做适当运算,产生新的结果写入流中
- 完成处理所关心的数据的处理逻辑,将数据汇聚归并成最终关心的形式
RxJava 支持从已有的数据结构中创建 Observable, 我们可以很方便的使用 from/just 或者 create方法创建出来,
他们可以同步地一次调用onNext方法通知感兴趣的订阅者;在所有的数据都通知完毕的情况下,则会调用 onCompleted() 方法通知订阅者。
组合和变化 Observable
RxJava 支持我们方便地连接或者组合多个Observable, 考虑如下的 groovy 代码
def simpleComposition() {
customObservableNonBlocking()
.skip(10)
.take(5)
.map({ stringValue -> return stringValue + "_xform"})
.subscribe({ println "onNext => " + it})
}
它的处理流程其实是如下的流水线处理

Kafka Streams
Kafka本身(可以参考前一篇文字)就可以看作是一个流式处理平台。同时它还提供了专门的流处理API,其特性如下
-
Kafka Streams 本身是一个客户端的库,可以看作是一个用户端程序而不是其平台核心部分;它本身被设计为可以很容易地嵌入到用户端的Java程序中,方便部署和集成。 除了Kafka平台本身,它不依赖于其他的库或者系统;同事又能依托于Kafka平台提供的可伸缩性和一致性保证提供高可靠的实时处理能力。
-
支持流处理中插入自定义的本地状态,从而结合传统的过程式编程的本地状态的便利;当然破坏了纯函数性编程无状态的假设会带来复杂的问题,以提高性能; 各种取舍需要用户自己去选择。
-
Stream是Kafka Streams提供的最重要的抽象,它表示无边界、持续更新的数据流;一个流是有序而可重放的,其中的数据是由按时间顺序的不可变的数据序列组成; 其中的一条数据或者记录被定为为一个Key, Value对。 -
建立在stream之上的应用程序可以看作是由一个或者流处理对象(stream processor)组成;这些流处理对象是高度可组合的,它们可以将一个或者多个流作为输入, 经过一定的函数变换产生一个或者多个流对象输出。 这里的两种例外情况是被称之为
Source和Sink的处理对象;Source可以从Kafka平台中读取某个Topic作为输入经过处理后,产生新的数据流, 而Sink可以从上游的流中拿到数据,作处理之后,将结果写入一个特定的Topic上。
Kafka Stream的流处理拓扑结构如下图
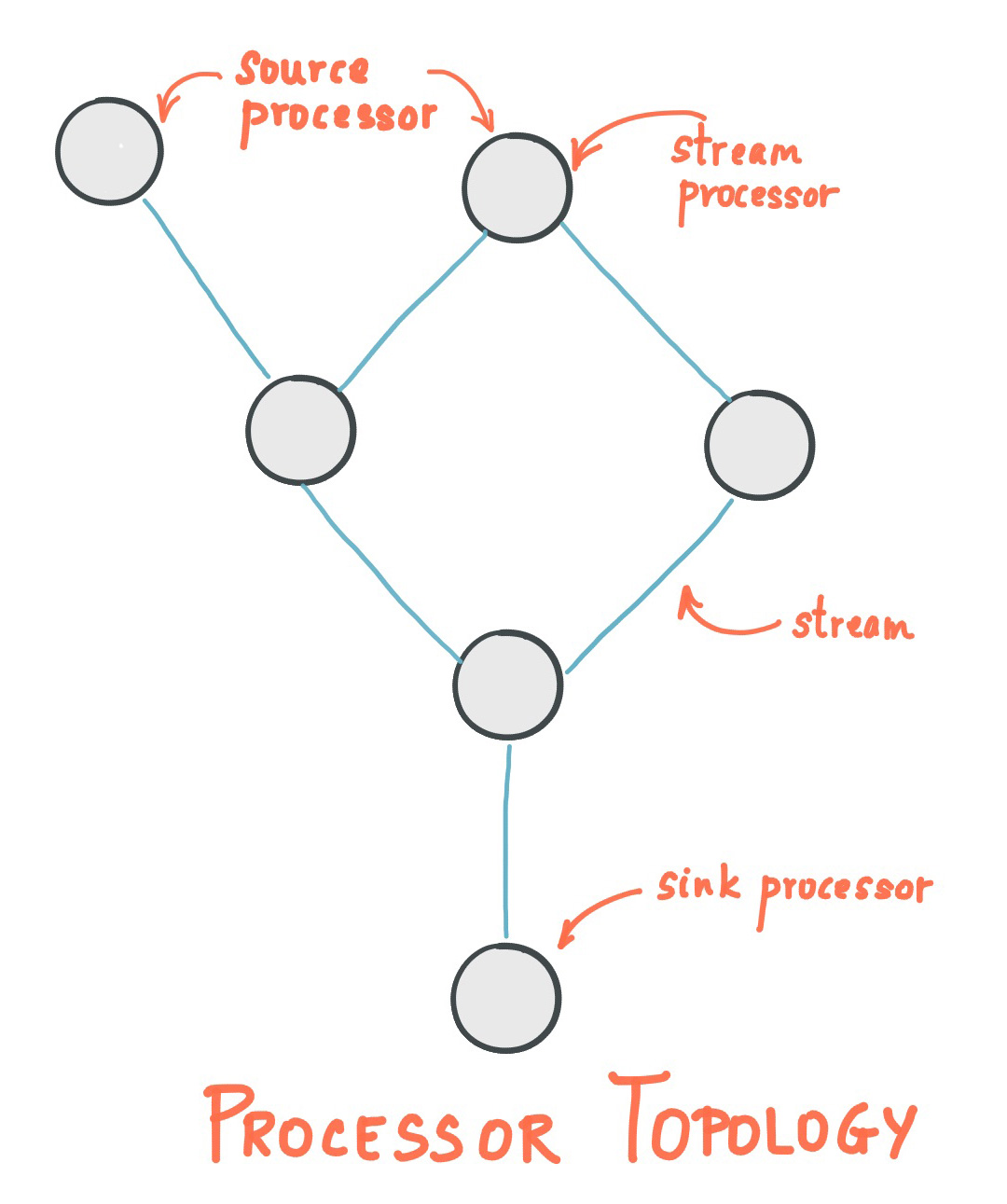
两种流处理技术
Kafka Streams提供了两种方法来操作流处理逻辑
- 专门的领域语言(DSL) 提供了基于Steams的高级API来转换流;用户可以用这些API的组合来完成自己的应用程序逻辑。
- 相对底层一些的 Processor API,适用于用户想自己定义自己的流处理逻辑的情况;这里我们只粗略看看DSL的特性和使用。
DSL支持基于Streams和Table的抽象,有三个主要的接口
KStream是基本的数据流对象KTable是一个二维表,可以方便地用在需要数据连接或者分组的情况GlobalKTable是一个全局的表,其本身可以和Kafka的数据分块等能力结合起来用
KStream用来表述流的概念,而后两者用来对应于数据表结构。基于 StreamsBuilder 类,我们可以很方便地将Kafka中的某个topic数据读加载到流中或者数据表中。
这些接口提供了丰富的变换操作(方法),其中一些变换方法会产生一个新的KStream而另外一些则会产生新的KTable。
从实现上看,这些接口都是用泛型技术实现的,并且是强类型的。
所谓的流变换可以分为两类:无状态的后有状态的。无状态的变换支持诸如 map/filter/flatMap/filterNot/foreach/groupByKey/selectByKey/toStream等操作;
其中toStream可以实现从KTable到KStream的转换;而groupBy则返回分组过的流或者数据表。
有状态的变换除了将传入的流作为输入外,还需要一个额外的状态数据存储参与到变换处理过程中;
比如一个window操作会在处理过程中读取window信息来确定输入流中的哪些数据应该被处理并将其结果放置在输出流中。
有状态的流变换包含如下几种
- 聚合
- 连接操作(Join),可以将其想象为SQL的表连接
- 上述的window操作
- 自定义的流处理变换操作,由于是自定义的所以可能是有状态的
它们之间的关系可以参考下图
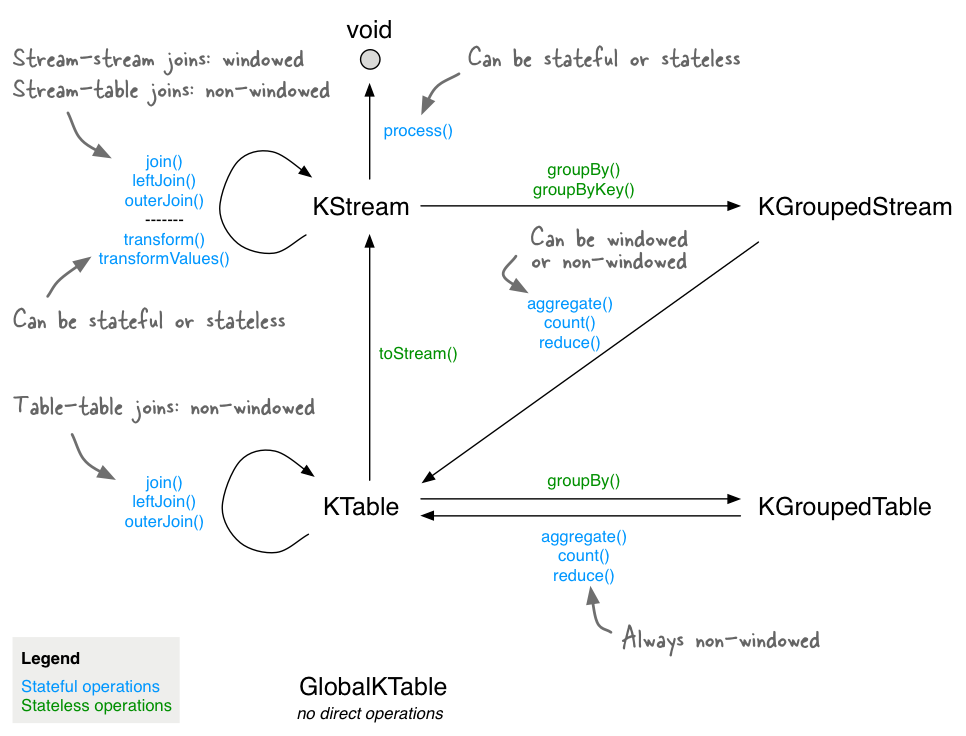
一个简单的例子
下面是一个简答的Java8的程序,用于统计某个文本行中的词出现的次数
// Assume the record values represent lines of text. For the sake of this example, you can ignore
// whatever may be stored in the record keys.
KStream<String, String> textLines = ...;
KStream<String, Long> wordCounts = textLines
// Split each text line, by whitespace, into words. The text lines are the record
// values, i.e. you can ignore whatever data is in the record keys and thus invoke
// `flatMapValues` instead of the more generic `flatMap`.
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
// Group the stream by word to ensure the key of the record is the word.
.groupBy((key, word) -> word)
// Count the occurrences of each word (record key).
// This will change the stream type from `KGroupedStream<String, String>` to
// `KTable<String, Long>` (word -> count).
.count()
// Convert the `KTable<String, Long>` into a `KStream<String, Long>`.
.toStream();
RxCpp
RxCpp 提供类似了和 Ranges-v3 库类似的管线操作,其处理方式本质上也是反应式的。
由于C++支持运算符重载,| 操作符可以天然地作为管道操作符拿来用,而现代C++语言对函数式编程和Lambda表达式的丰富的表达能力使得写出可读性好的代码不算什么难事。
下面是其项目文档中的一个例子,实现如下一个解析任务
- 给定一个二进制文件作为输入,其中存放的是一段不等长字符串构成的二进制表示,可以有多行;每行用之间回车符号隔开 ;输入长度被分割为固定长度的行
- 要求解析给定的输入,将二进制数表示的字符打印出来,并且每一行对应于原输入中的一行
输入的格式如下(假设一行有17个字符的二进制数表示 )
66 66 66 66 66 66 66 66 66 66 66 66 66 66 66 66 66
13 67 67 67 67 67 67 67 67 67 67 67 13 68 68 68 68
68 68 68 68 13 69 69 69 69 69 69 69 69 69 13
对应的输出应该为
BBBBBBBBBBBBBBBBB
CCCCCCCCCCC
DDDDDDDD
EEEEEEEEE
产生一段随机的字符输入可以用RxCpp的方式写为如下的函数式代码
random_device rd; // non-deterministic generator
mt19937 gen(rd());
uniform_int_distribution<> dist(4, 18);
// for testing purposes, produce byte stream that from lines of text
auto bytes = range(0, 10)
| flat_map([&](int i) {
auto body = from((uint8_t)('A' + i))
| repeat(dist(gen))
| as_dynamic();
auto delim = from((uint8_t)'\r');
return from(body, delim)
| concat();
})
| window(17)
| flat_map([](observable<uint8_t> w){
return w
| reduce(vector<uint8_t>(), [](vector<uint8_t> v, uint8_t b){
v.push_back(b);
return v;
})
| as_dynamic();
})
| tap([](vector<uint8_t>& v){
// print input packet of bytes
copy(v.begin(), v.end(), ostream_iterator<long>(cout, " "));
cout << endl;
});
这里虽然有多个管道操作,不习惯函数式编程风格代码的程序员可能看起来有些头晕,好在只要我们加上恰当的缩进,在熟悉RxCpp库的命名的情况下,代码的逻辑还是比较简单明了的
range(0, 10) 先生称一个Observable对象作为流的起点,内部会一次产生0,1,2,…,10发布给流,通知其后的 subscriber, 后边的管道操作符连接了流处理的下一个环节。
接下来,用给定的字符得到一个对应ASCII码,然后用 repeat函数经给定的字符做重复,产生4~18个重复的字符,as_dynamic则是一个特殊的函数用于解决C++类型安全方面的一些问题。
这是一个字符行的二进制串,然后我们还需要用换行符将其连接起来,from 的双参数形式可以产生一行新的 Observable 对象,用第二个参数作为分隔符连接第一个Observable,
进而这里的多个行便被连接成一个整体的 Observable对象给后续处理了。
由于我们希望每一行的输入仅有17个二进制串,紧接着的 window函数就是用来将输入的流按照固定的长度分隔为固定长度的行的;需要留意的是每一个字符的长度可能是4~18的一个随机值,
这个在前面repeat的时候便确定了。flat_map可以将lambda表达式封装的实际的 observable 提出出来。
有了上面这些按行分割好的集合,接下来的任务是需要将这些记录保存到一个容器中,便于后续解析处理,因而后续的一个flat_map()调用针对前面的集合,
采用reduce算法收集一个一个的字符并以行为单位放入容器中,最终的流会每次产生一个vector<uint8_t>待后续处理。
出于调试的便利,我们同时用tap函数安插一个方便调试的打印操作,该函数本身不会修改流的数据内容。
下面的代码则完成一些变换逻辑,用更多的中间变量会使得代码更容易理解一些,当然代码就不如上面的输入部分那么紧凑了。
首先我们需要一个工具函数删除给定字符串中的空格字符,用一个lambda表达式可以很容易的写出来
auto removespaces = [](string s){
s.erase(remove_if(s.begin(), s.end(), ::isspace), s.end());
return s;
};
接下来我们就可以针对上面已经生成好的bytes流,按照回车符号进行拆分,过滤掉输入中的空格字符,拆分过程可以用C++标准库的cregex_token_iterator来完成,
并将结果用迭代器封装访问,而C++11的移动语义可以额外的减少临时字符串的开销。concat_map将所有的去掉了换行符的字符串连接起来,交给流的下游,
然后完成过滤空格字符串的操作。
最后我们需要将处理好的串再加上回车符号,并最终输出,加上publish和ref_count可以使得我们写2个单独的订阅者,第一个自动建立流的连接,
最后一个订阅者处理完毕后自动关闭流. 代码如下
// create strings split on \r
auto strings = bytes
| concat_map([](vector<uint8_t> v){
string s(v.begin(), v.end());
regex delim(R"/(\r)/");
cregex_token_iterator cursor(&s[0], &s[0] + s.size(), delim, {-1, 0});
cregex_token_iterator end;
vector<string> splits(cursor, end);
return iterate(move(splits));
})
| filter([](const string& s){
return !s.empty();
})
| publish()
| ref_count();
由于最后一行不像前边的行一样有一个额外的回车符,我们需要将其分拣出来,使用filter和window_toggle()可以很方便地将二者进行分组,
然后再将结果用sum连接起来并删除中间的空格字符。
// filter to last string in each line
auto closes = strings
| filter( [](const string& s){
return s.back() == '\r';
})
| Rx::map([](const string&){return 0;});
// group strings by line
auto linewindows = strings
| window_toggle(closes | start_with(0), [=](int){return closes;});
// reduce the strings for a line into one string
auto lines = linewindows
| flat_map([&](observable<string> w) {
return w
| start_with<string>("")
| sum()
| Rx::map(removespaces);
});
最后一段代码用于接产生好的流打印出来,直接传递给println即可
// print result
lines | subscribe<string>(println(cout));
看这里的代码,可以明显看到里面没有一个传统的过程式控制逻辑,没有分支、循环和判断,有的只是函数定义、调用和流连接操作。 如果熟悉Rx系列库的API,处理逻辑还是比较清晰明了的。
Reactive Spring
Spring 5.0 框架的一个重心就是增加对FRP风格的架构的支持。 Spring框架之所以流行,一个很重要的原因就是其易用而又性能极好的MVC框架可以很好地替代传统的servelet-API,虽然Spring MVC可以很好地解耦一部的HTTP请求, 但是在不破坏既有框架的前提下增强非阻塞的IO模型却碰到了不少困难。另一方面,基于注解的MVC工具带来了更具可读性的代码和清晰的业务逻辑, Spring 5.0在尽力不破坏既有注解的前提下,实现了一个底层的Reactive Engine。
同时Spring还发布了一个基于JVM平台的反应式流处理规格说明,尝试将改编程范式在JVM平台上实现标准化。 目前该规格致力于实现多种异步组件驱动在JVM平台之上的互操作性,Flow接口已经加入到Java9的中; 它由4个接口,一些rule 以及一个TCK组成
Publisher用于产生可以无固定边界的元素的序列,这些元素可以被发布给特定的订阅者Subscribe用于从Publisher中接收数据更新Subscription用于表述Publisher和Subscriber之间的订阅关系并可以对数据的处理做控制,有request和cancel方法Processor用于表述流处理的中间状态
其它语言和平台
对于其它编程语言环境和平台,微软的开源项目Reactive Extensions提供了丰富的支持。
Leave a Comment
Your email address will not be published. Required fields are marked *