
用Java Flight Recorder来调优JVM性能
随着Java程序在后端压倒性的普及,其性能本身早已经无人质疑;然而一个经常不为人道的事实是,Java平台上的程序不是天然就具有很高的性能; 因为Java语言显著降低了程序员的准入门槛,真正到系统性能这一块,仍然需要大量的调试和优化,即所谓的JVM性能调优。
Java Flight Recorder(后文简称JFR)是Oracle官方推出的商业环境的性能调优利器;其本身对运行期系统的侵入性很小,同时又能提供相对准确和丰富的运行期信息; 合理使用改工具可以极大地提高工作效率。本文就个人工作环境中的一些实际使用情况做一简单的总结。
基本工作模型和采样
JFR本身是基于周期性对JVM虚拟机的运行状况进行采样记录的,其采样的频率可以通过其参数传入;只是需要留意的是,采样间隔越小对系统的性能干扰就越大。 和传统的JProfiler/VisualVM这些基于JMX的工具所不同的是,JFR记录的信息是近似而非精确的;当然大部分情况下这些模糊性信息就足够说明问题了。 对于大部分场景下,这些近似信息反而可以更容易发现一些真正的问题。
要想使得JFR能够产生采样信息,首先需要确保你采用的JVM是Oracle的JVM,否则JFR也不认识虚拟机的内部工作机制;此外还需要在JVM的启动参数中开启商业特性的开关, 并开启JFR;相关选项很容易在官方文档里找到,这里就不赘述了。 额外需要注意的一点是,你必须有Oracle的商业使用许可,否则是不能用的。
开启JFR选项后,有两种方式可以产生采样文件以便时候分析
- 在启动参数里指定启动后即开启采样;这种方式对于想分析启动时候性能的情况非常有用;只要在参数中指定采样间隔,时间以及保存的文件路径即可
- 通过
jcmd的JFR命令来按需产生采样;该方式更适合在程序启动之后按需产生采样。Oracle JDK自带的Java Mission Control程序可以挂在本机上运行的Java程序上做观测, 本质上也是这种机制。
产生的采样文件可以在本地机器上使用Java Mission Control工具打开做事后分析。
哪些信息被采样保存
基本上所有有用的信息都被保存下来了;最主要的概要信息保存在General/Overview里边。
General面板
以下是一个具体的CPU在某段时间出现繁忙的例子,这种采样在繁忙的后端服务器上可能是比较常见的,因为大部分情况下我们需要尽可能占尽可用的CPU时间来追求更高的吞吐率。
当然如果CPU已经满负载运行,而吞吐量又不太理想的时候,详细深入的分析就变得更为重要。
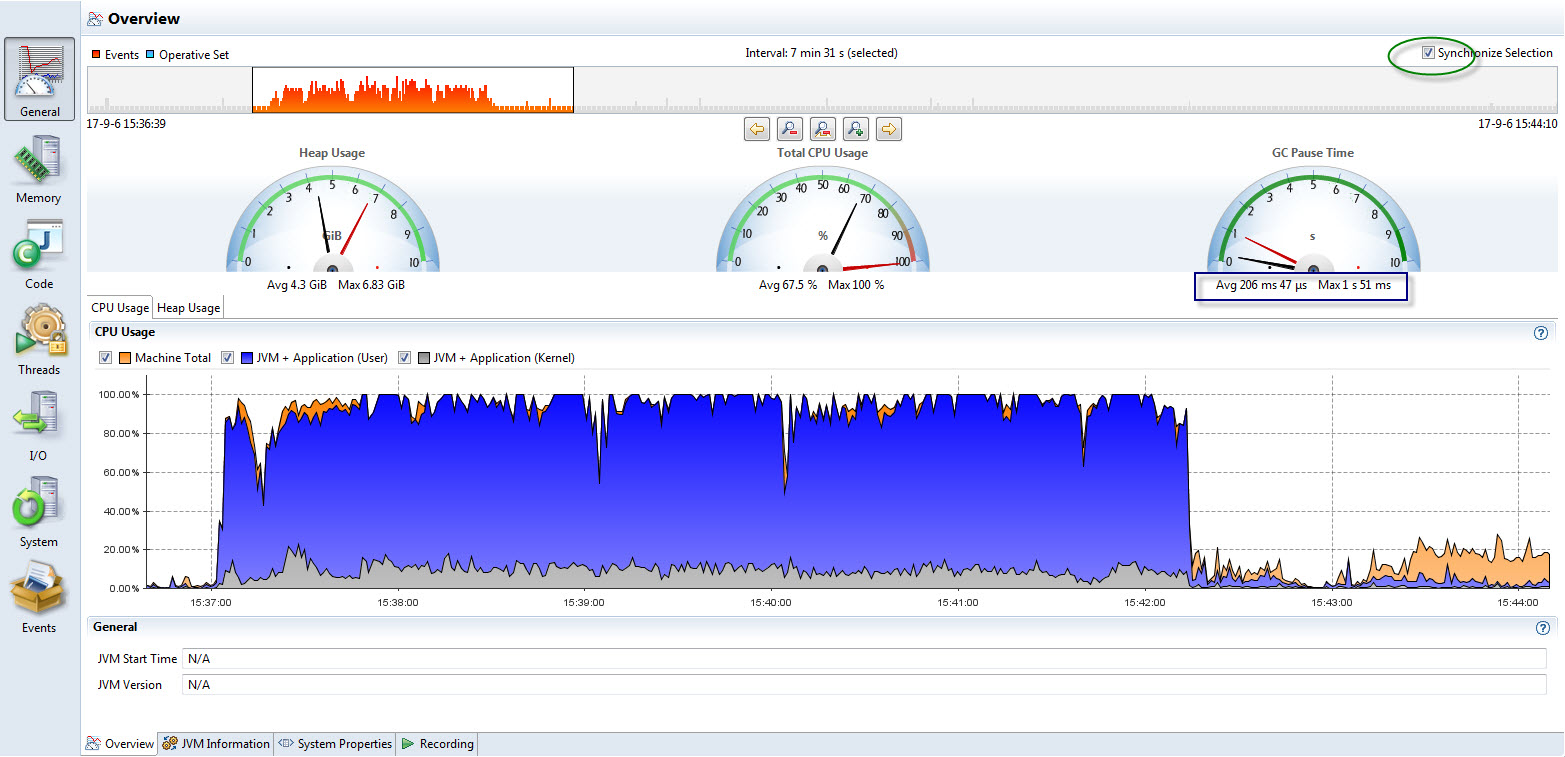
首先映入眼帘的是一个常常的时间轴和系统时间图,开始时间和结束时间都可以按需选择; 如果选定了synchronize selection,则所有的信息显示都会随着选择范围的变化而实时刷新。 这一机制非常灵活有用,因为很多时候我们都需要根据基本分析和直觉印象去选择某些特点的时间来对比观察。譬如在追求高吞吐率的场合,发现CPU没有用满但是吞吐率有上不去的时候, 可以选择CPU有锯齿的地方,详细去查看特定的时间点内发生了什么。
接下来的三个大大的仪表盘会给出Java的堆内存、CPU使用、GC停顿时间的平均值和最大值;从而可以看到系统在给定时间内,JVM的内存/GC情况和CPU利用概况。
最下方的部分则会显示一个更详尽的CPU使用图表曲线,在任何一个时间点(依采样频率而定)机器总的CPU利用率、JVM和用户程序在用户态、内核态的CPU使用情况。 对于追求高吞吐率的后端程序而言,这些信息值得仔细查看。
最后一部分则显示了JVM的概要信息,包括其启动时间,JVM的具体版本等。除了这个概要页面,还有2个总体的标签页,分别显示具体的JVM命令行选项(包括默认没有设置但是传入给JVM的项), JRE环境的属性和变量,采样记录信息如线程上下文切换计数的时间间隔等;这些信息在分析一些具体的性能参数的时候,是很重要的参考。
内存面板
由于Java中的内存分配和回收是JVM帮助程序员做的,Java性能调优的很大一部分工作是和内存调优密切相关的。 内存面板则是根据运行期的采样数据将JVM的GC相关的数据汇聚显示出来;和其它的类似,同样是顶层的时间轴曲线可以依据选择来同步其他图表。
中间的部分显示详尽的内存使用概览,包括总共可用的机器物理内存、已经使用的物理内存、提交给OS的堆空间、已经使用的对空间等。 锯齿状的曲线就是已经使用的堆空间随着GC的活动而动态变化的历史。如果图表中出现比较粗的“柱子”图样,则表明GC的工作情况需要具体仔细查看了。
最下栏则显示了当前GC的配置情况,如初始、最大的堆空间大小,不同的代的空间分配、GC活动的统计技术以及空间分配的概要情况。 大部分情况下,我们更多关注运行过程中间的GC统计指标,包括总共的收集次数,最小、最大以及平均的停顿时间; 这些数值当然都是越小越好了;因为任何的GC活动都会挤占应用程序的可用资源。
GC活动信息和收集细节
一些额外有效而更细节的信息则会显示在单独的标签页中,包括这么几类
- 垃圾收集详细信息:所有的GC活跃情况,以ID为标号详细地显示出对应的停顿时间,收集的类型,回收的原因,开始/结束时间,以及统计性的最长停顿时间等。 这些信息很多和具体的GC算法是密切相关的
- GC的停顿情况:同样针对的是每一个GC活动,针对具体的回收事件,对具体引用类型的收集停顿间隔以及相应停顿处理活动的开始时间信息等; 虽然不能看出具体的回收对象,但也足以看出大概的整体停顿比例和时间,对耗时的GC活动做定性的分析还是足够有用的
- 对象引用情况:简要的显示了某次GC活动的时候,各种类型的对象引用的个数,可以辅助上一项,提供了更细节一点的数量统计
- 堆空间的变化情况:回收前后的堆空间情况,和
jstat提供的信息一样
下图是上面同一个采样的GC信息,其中可以看出GC的活动对于CPU繁忙时段的贡献是不大的,基本可以排除GC对性能的影响
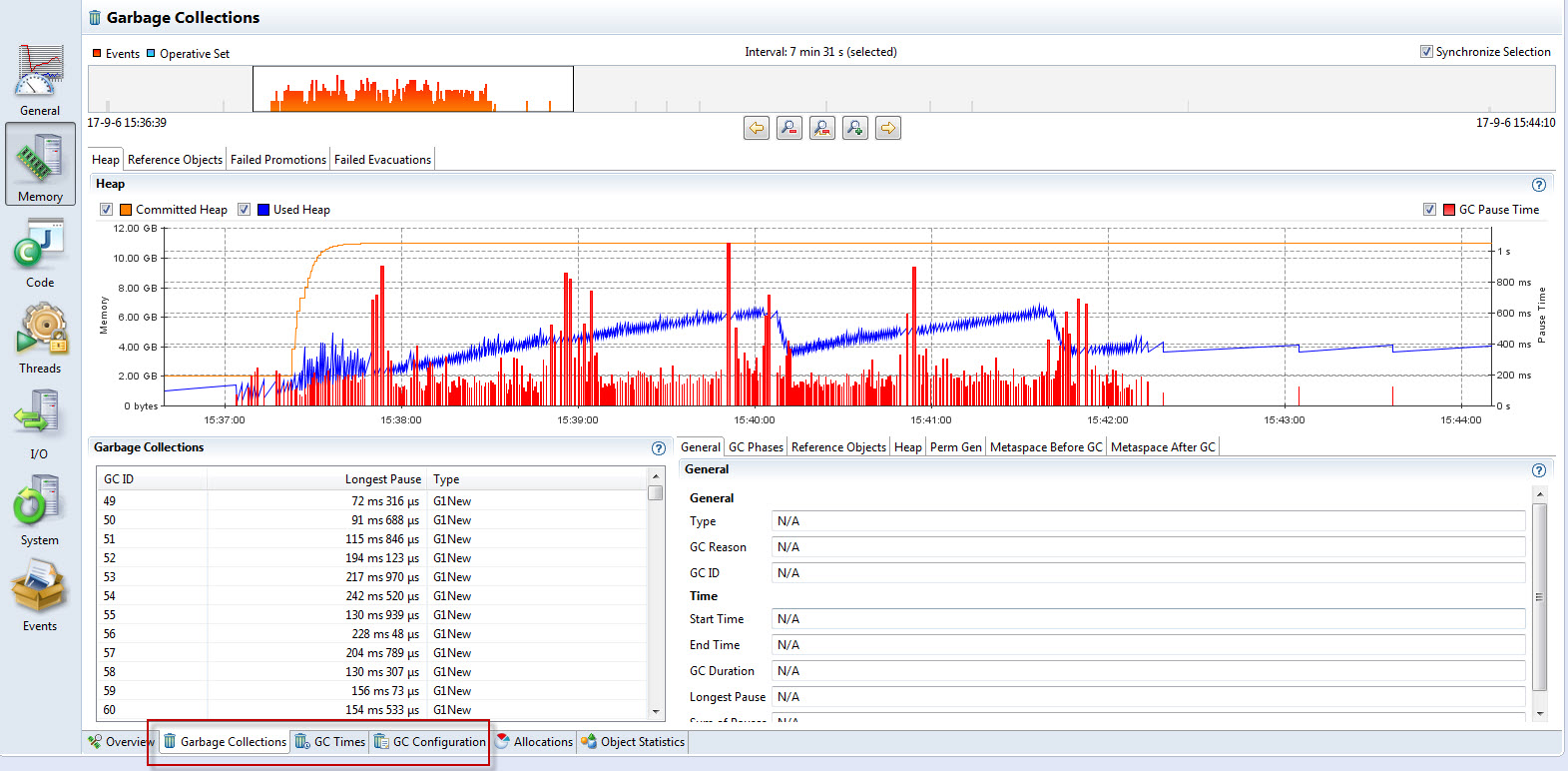
详尽的GC时间统计信息
GC时间统计页面则从时间的角度给出各个GC的代在收集过程中所占用的时间,最小、最长、平均停顿等。 这些统计同样是按照新生代、老生代、以及所有的收集活动耗费的时间来呈现的。同样这些信息和具体的GC算法是密切相关的,需要根据GC算法的配置来综合使用。
同样是上面的程序运行期的一个采样,其GC时间信息如下
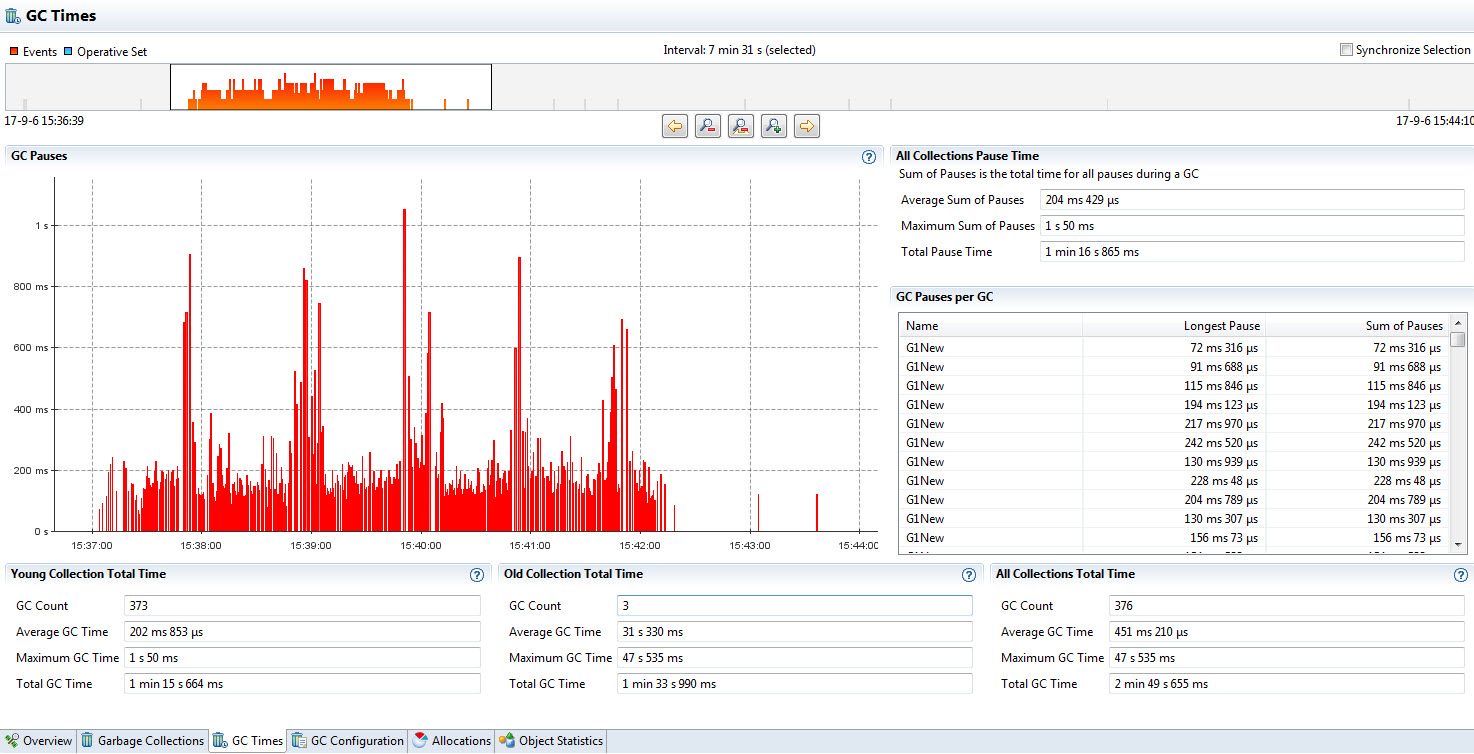
上述采样表面,大部分GC活动事件属于新生代GC,即回收临时对象的常规动作;老生代GC仅仅有3次,并且占用的时间并不算长。 注意这里采用的是G1 GC算法,老生代的回收并不会完全阻塞应用程序线程的运行 - 具体的时间信息可以结合应用程序的log时间戳打印综合确认。
GC算法相关的具体配置细节
GC算法的参数配置则可以在其相邻的标签页找到,它给出了更为详尽的算法配置参数,包括
- 新生代、老生代对应的收集算法
- 并发收集的线程个数 (可能对某些算法不适用)
- 是否开启并发收集
- 是否允许应用程序显式地调用GC
- GC被允许运行的时间占所有可用CPU时间的比率的上限值(G1等新型的GC算法支持这种约束,防止GC过分活 跃)
- 各个代的空间信息,包括初始空间大小、最小对空间大小、最大空间大小,以及对空间的地址大小、指针压缩情况和对象对齐情况(对64位的Java程序尤为重要)。 新生代的配置还会提供诸如TLAB空间占用的情况和配置,以及默认隔多长时间会将仍然在引用的对象挪到老生代等信息。
同样是上面的采样,其GC配置信息如下
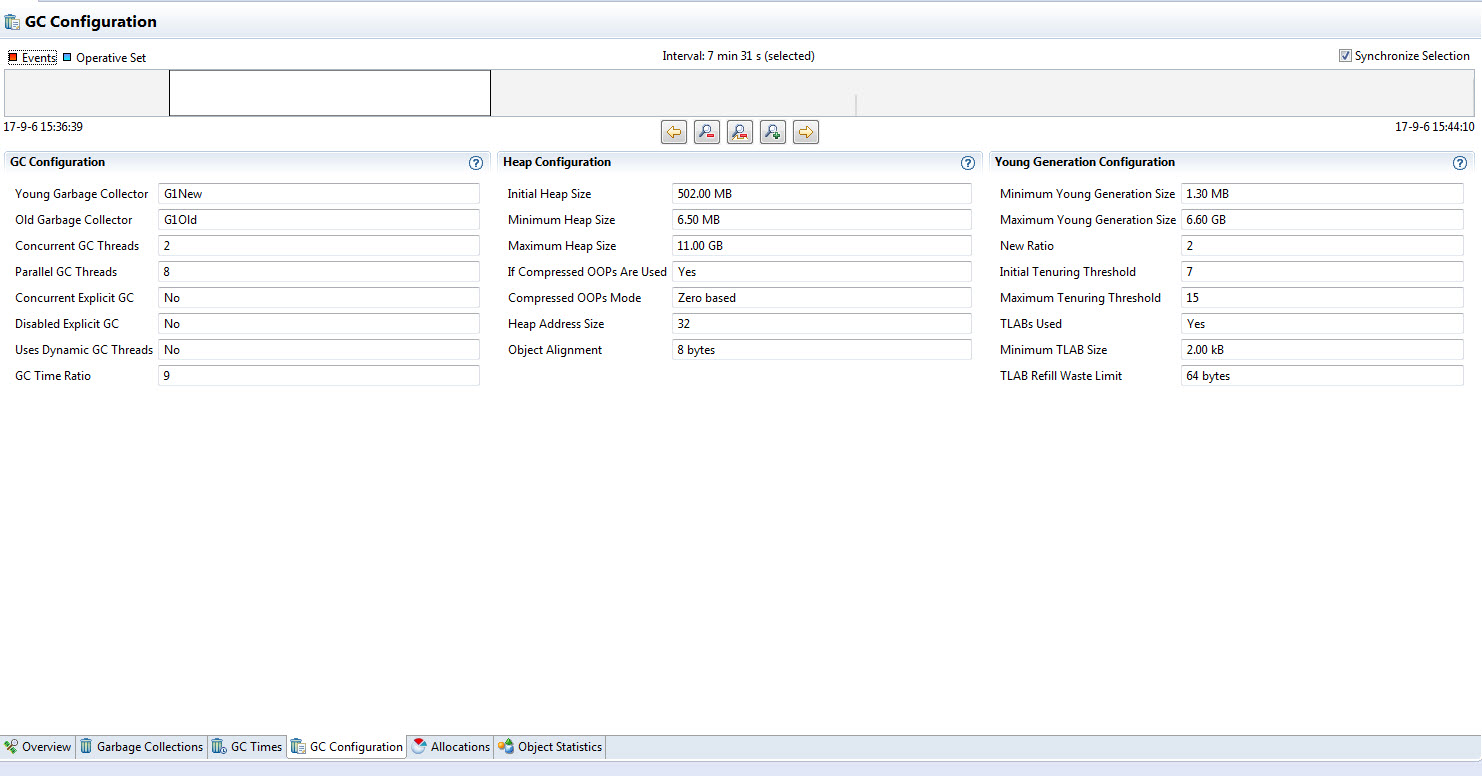
以上这些复杂的信息对于深入的内存分析和针对是非常宝贵的; 譬如如果应用程序中生存期较长的对象并不多(面向对象设计提倡大部分的运行期对象是朝生夕死),然而老生代却有比较大的压力, 就要怀疑是否是部分关键逻辑运行时间过长,导致经过数次新生代回收之后,仍然没有被释放出去,从而导致进入老生代被老生代的回收活动处理。
代码面板
代码面板则是基于采样得到的信息的代码执行情况给出统计分析结果。 需要注意的是,所有的数据都是依据具体的采样点,具体的线程当时正在运行的的函数调用栈的具体状态来计数并累加的。
比如某个调用栈有10次被捕获到,那么相应的栈上的所有的函数的计数都会被记为10;这样得到的结果和实际代码的CPU占用率比较类似,但是并不完全精确。 所有的百分比数值都是相对百分比,其计算方法是用当前函数的采样数和整体(线程或全局CPU采样数)的采样数相除。
代码概览
概览页面会显示按照Java的包情况统计的采样数和相对总体的百分比;可以按照具体的列点击排序。最下边的视图则显式热点的类列表。 同样这些视图都可以根据选定的时间间隔来同步数据,使得我们可以方便的按照具体时间来分别查看CPU被占用在什么地方。
对于上述的程序运行采样,以下是其代码概要视图
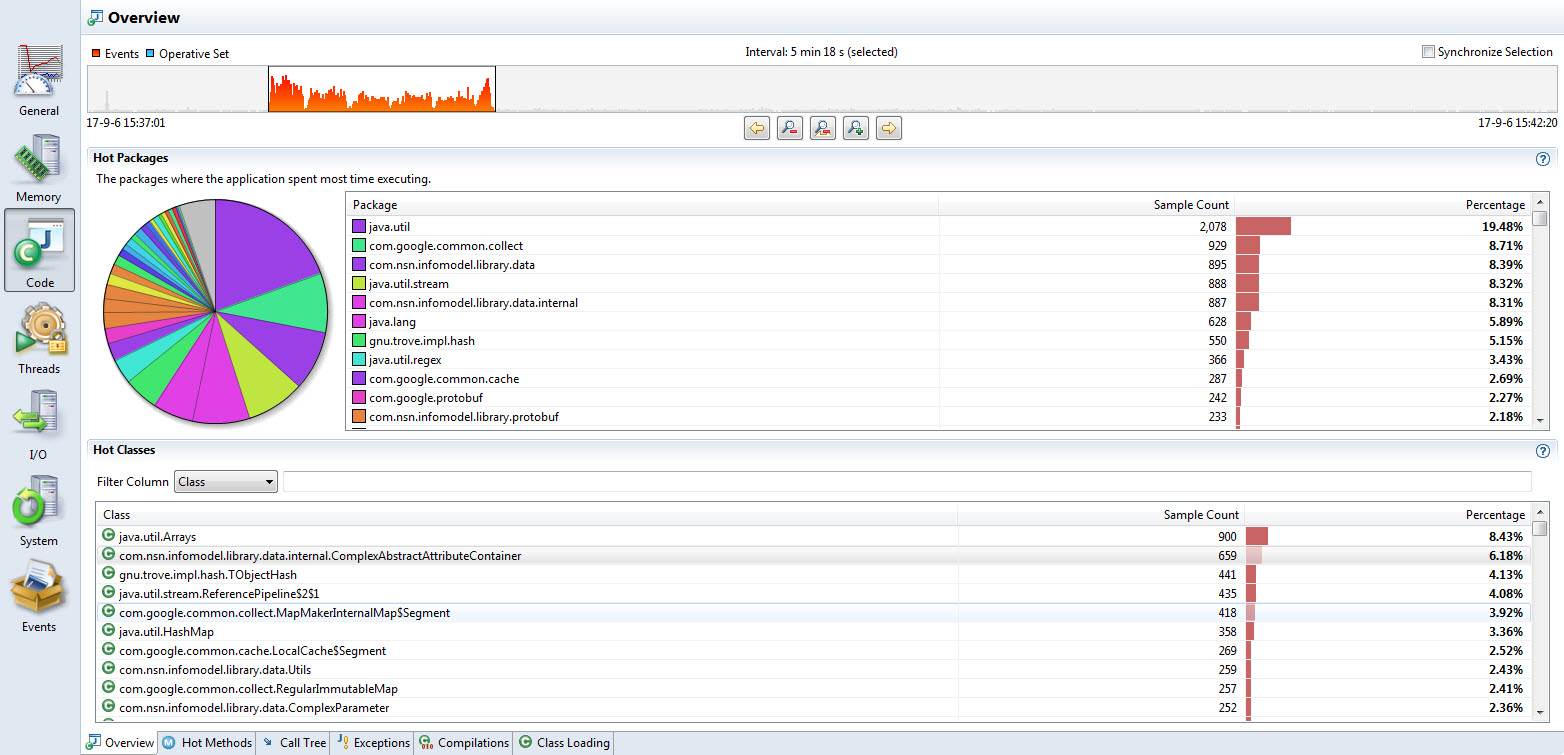
可以看出在给定的CPU热点时间,有超过20%的采样都提取到了java.util包的活跃样本,紧随其后的是一个Guava的工具函数包以及用户程序的一个基础工具库。
热点的类统计中,Java基本的Array类更是占据前列,这个在大规模的Java程序中是很常见的情况,同时也使得深入的分析变得困难而又必要,
因为对Java基础库或API的调用是被层层封装过的。
热点方法
热点方法标签则提供了基于调用栈的采样排序情况,可以点击具体的调用栈展开,具体查看可疑热点的调用情况从而做针对性的深入优化。
同样地对于上述的采样,其热点方法如下
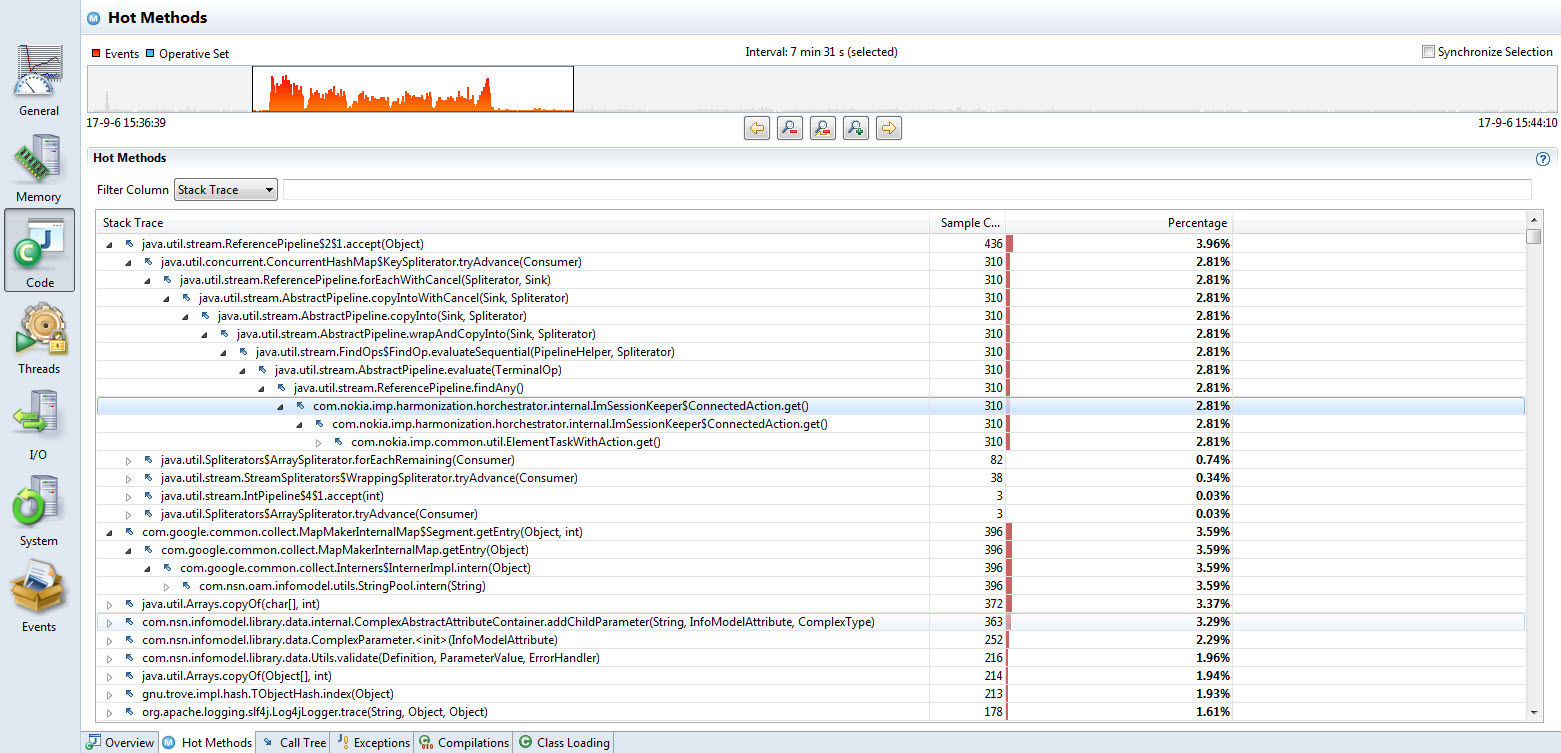
显然繁忙的CPU活动依然发生在Java API的内部,排在第一的是Stream API的pipeline操作,逐级展开JDK的封装,最终还是能找到应用程序的调用点。 同时每一个调用栈的右侧会显示对应的采样数和百分比。 这里的Stream操作会在运行的时候被多个上层函数所调用,则每个调用栈极其采样个数都被显示出来,可以顺势点开查看详情。
基于80/20原则,一般收效最大的是仅仅对占比最大的函数栈进行针对性优化;同时如果上一级函数的调用和字函数的采样个数不一致,说明函数内部的其它代码也需要仔细查看。 最麻烦的情况是80/20原则不太明显的时候;此时我们必须对多个可能的热点方法做优化,耗费的精力和时间就会更多。
回头看这个具体的例子,排行第一和第二的两个栈的采样数基本差不多,CPU时间耗费在哪里看起来似乎不是很明显;这是因为对应的采样是已经优化了一部分之后的中间结果。 令人惊讶的是,Guava的Interner API也占用了相当多的CPU时间;在CPU已经满的情况下,针对性的优化就要麻烦一些。
热点的调用栈
调用栈试图提供了和上述热点方法类似的信息,所不同的是其调用栈情况聚合了所有的API情况,譬如多个线程的同一个底层方法调用会被聚合在一起; 这样更容易从一个系统性的视角去理解程序实际运行时候的概况。
回到这个具体的采样样本,其热点调用栈如下
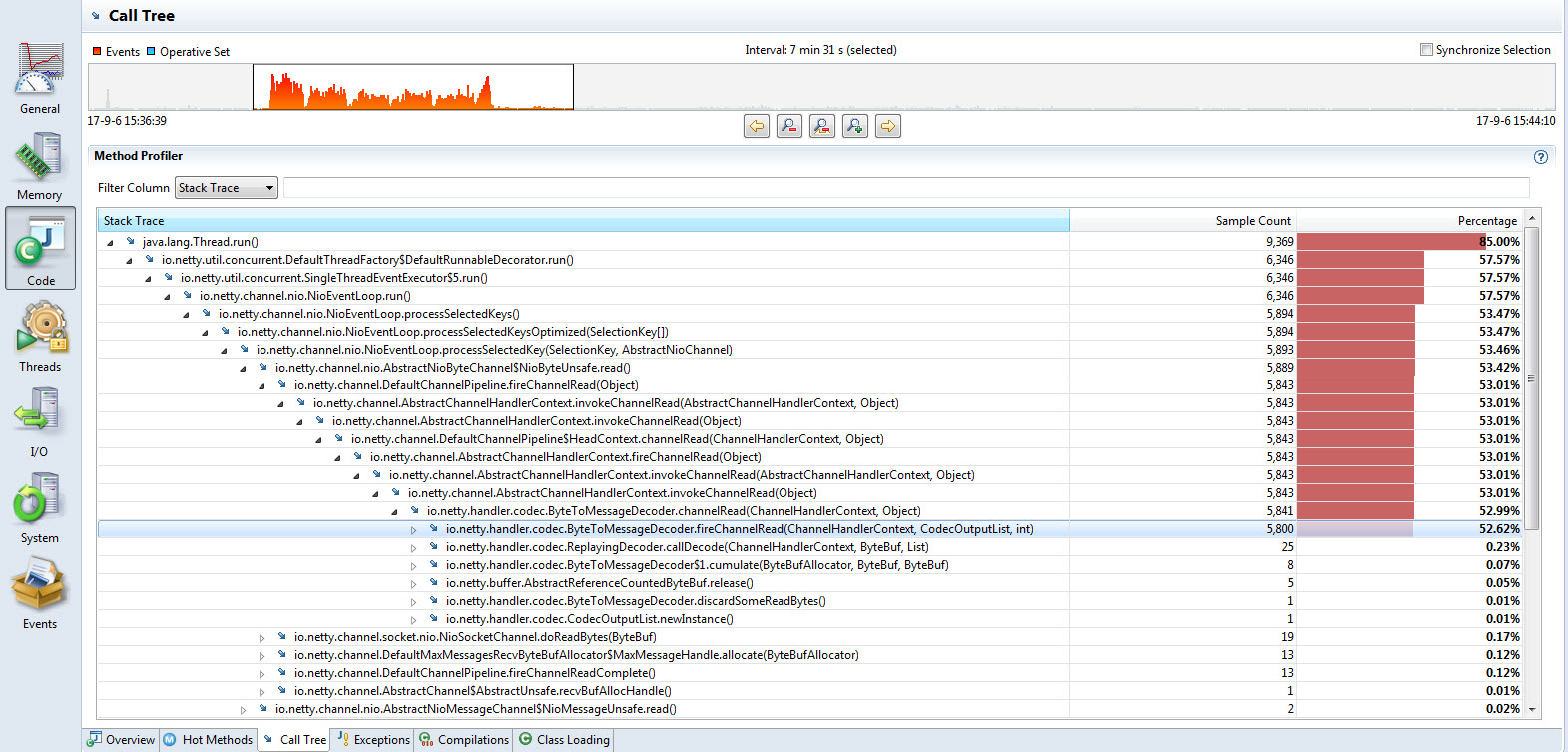
可以看出大部分的CPU样本落在Thread::run方法中,这在多线程的后端程序中是最正常不过的情形了。具体展开来看,大部分的时间花费在了Netty的管线处理中;
由于Netty的管线处理是采用调用链的方式逐级深入的,调用栈展开起来比较繁琐一点;最终展开的时候,可以看出这里的大部分CPU花费在了消息解码上。
线程面板
如今几乎所有的后端Java程序都是基于多线程的,运行期同时有数十乃至上百个线程在多核CPU上执行也是屡见不鲜的。
各色各样的第三方框架、库都会创建各种ExecutorServie实例,依据负载情况动态的创建或者调度线程。
线程面板从JVM线程的角度来分析采样的数据。其概要面板同样提供了最基本的CPU情况,并且支持根据时间选择来刷新其它标签页视图数据、表信息等。 其线程信息则显示线程数量的历史信息,包括后台线程和活跃线程数等信息。
热点线程
热点的线程显示在该标签页中,其中包含了丰富的信息
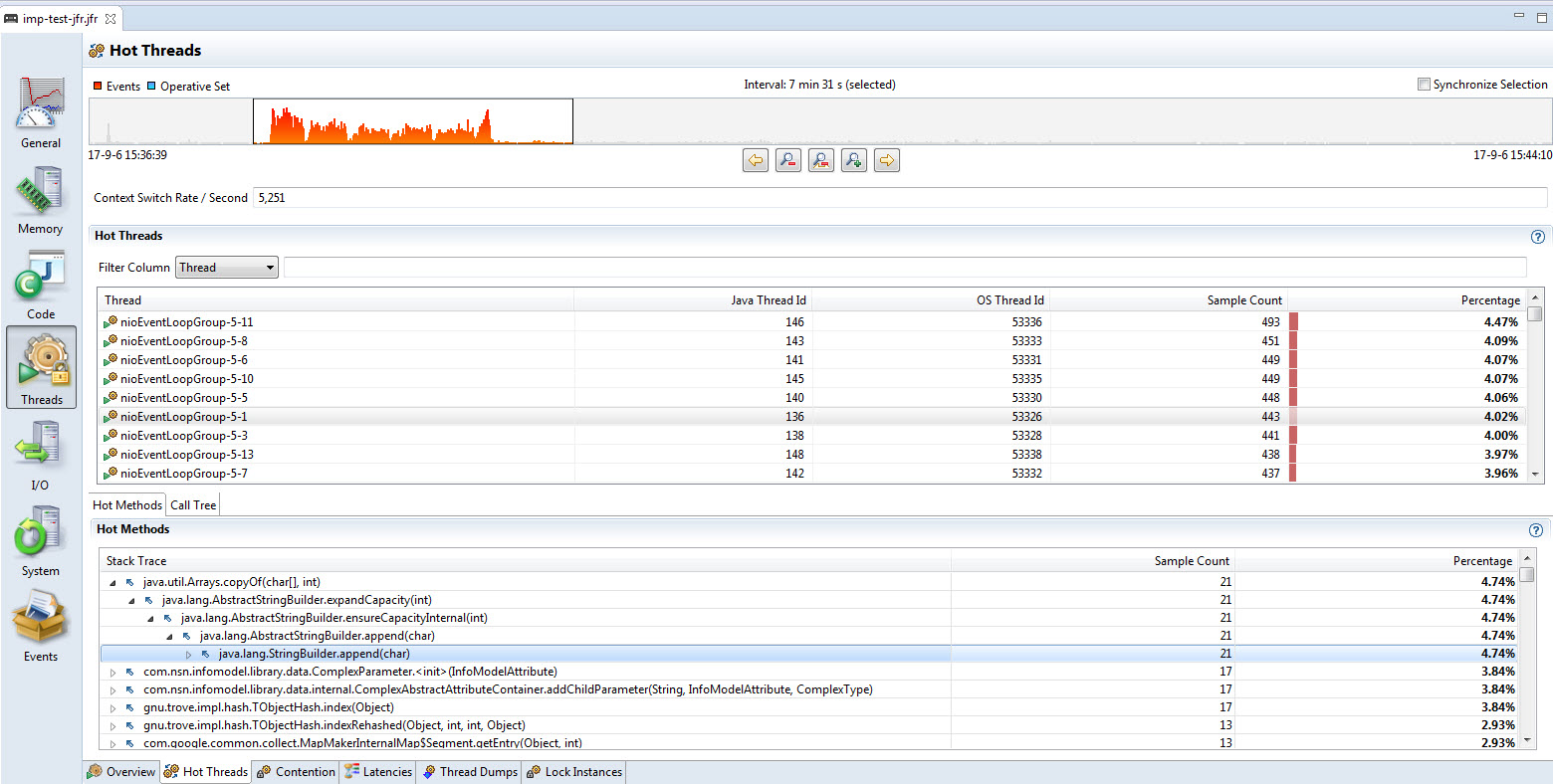
最上边的面板中显示地给出了线程上下文切换的频率;换算为多核的CPU就很容易看出来是否对应的采样时间内,CPU在忙于做上下文切换。 如果开启了很多个用户线程,这些线程又有比较粗粒度的锁,那么上下文切换的开销就很客观需要考虑优化。 比如这个例子中,在8个CPU核参与运算的情况下,CPU切换在2500多,平均Linux的10ms的时间片内,平均每个线程切换了3次多,属于比较正常的情况。
具体的热点线程数据和其调用栈情况,可以依据采样计数排序后详细查看。这个例子中,String的append操作消耗了大量的CPU,这个也算是大规模应用程序常见的情况。
线程竞争
同样是上边的运行其采样,线程的竞争情况视图为我们提供了更多关于CPU繁忙时候各个线程抢占CPU时间片的大概情况:
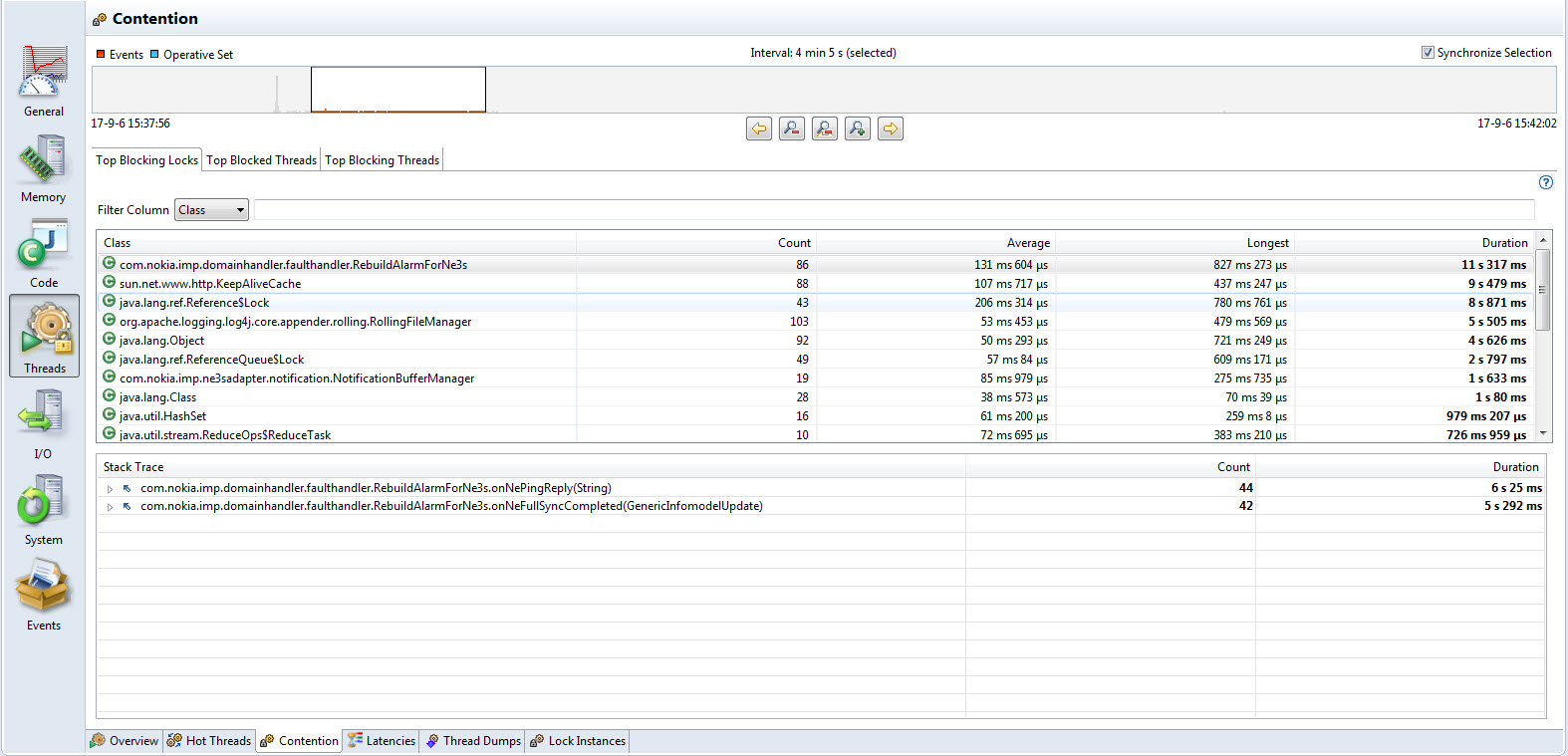
这里依据具体的CPU事件,JFR为我们提供了三个子视图来呈现多线程运行期的细节信心
- 竞争锁情况,按照其阻塞CPU运行的时间排序,分别显示了各个锁在给定的时间周期内等待的次数,最长、平均、总共的时间。一般时间越长需要优化的空间会越大,因为很多CPU时间被浪费在频繁等待和获取锁上边。具体的运行其堆栈可以在下方的细节视图中具体查看
- 被阻塞的线程信息,列举了这些等待获取锁的线程的信息,时间、堆栈等
- 阻塞其他线程的线程信息,和上一个类似,只是显示的是占有共享锁而阻塞了别人的线程的相关信息
时延和锁竞争情况
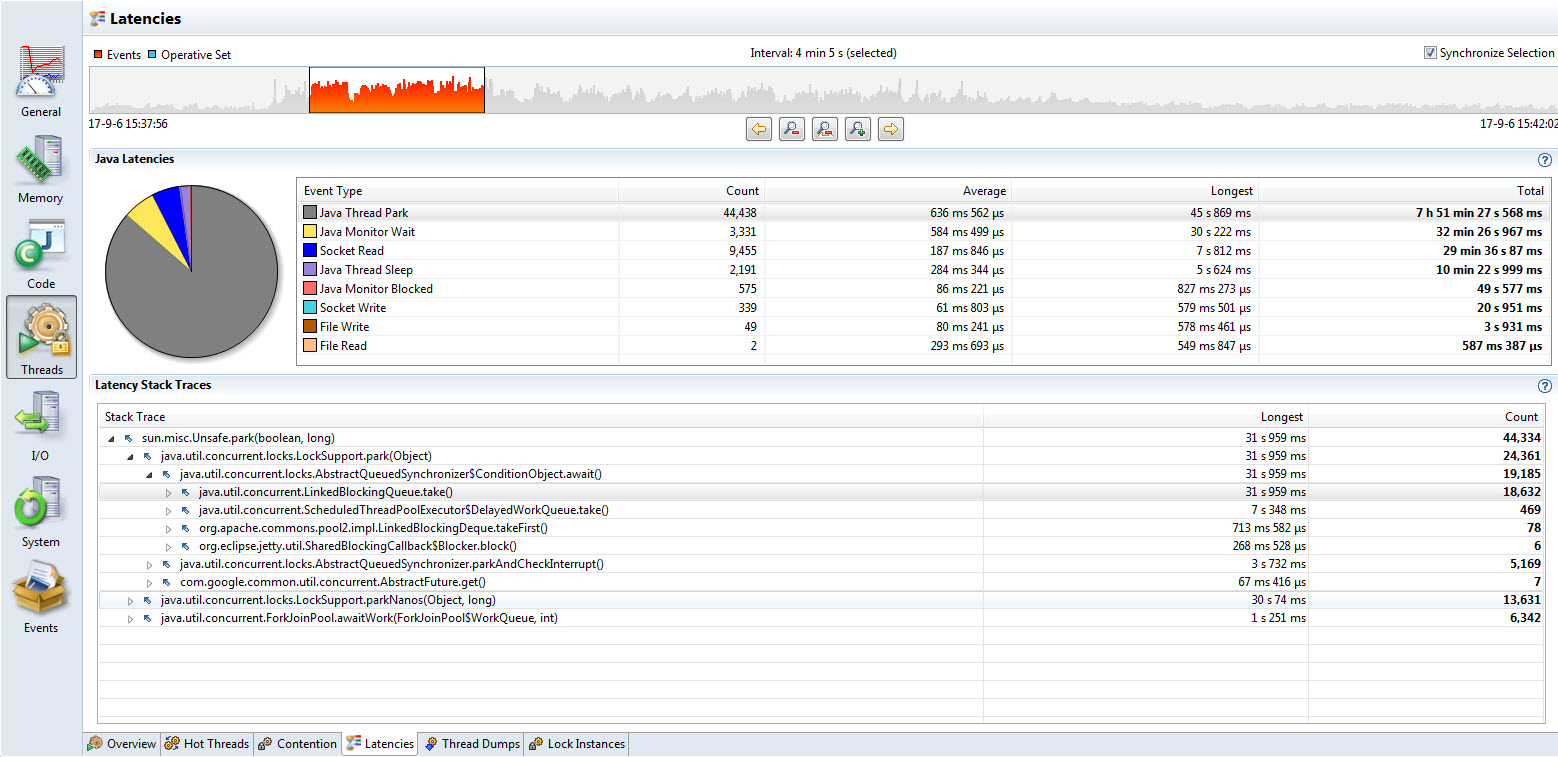
线程的时延信息则从运行期所采样到的操作等待时间长短的维度呈现一些排序和统计信息,同样可以依据其数目、平均等待时间以及最长时间等因素来排序查看对应的运行其堆栈情况,如下图
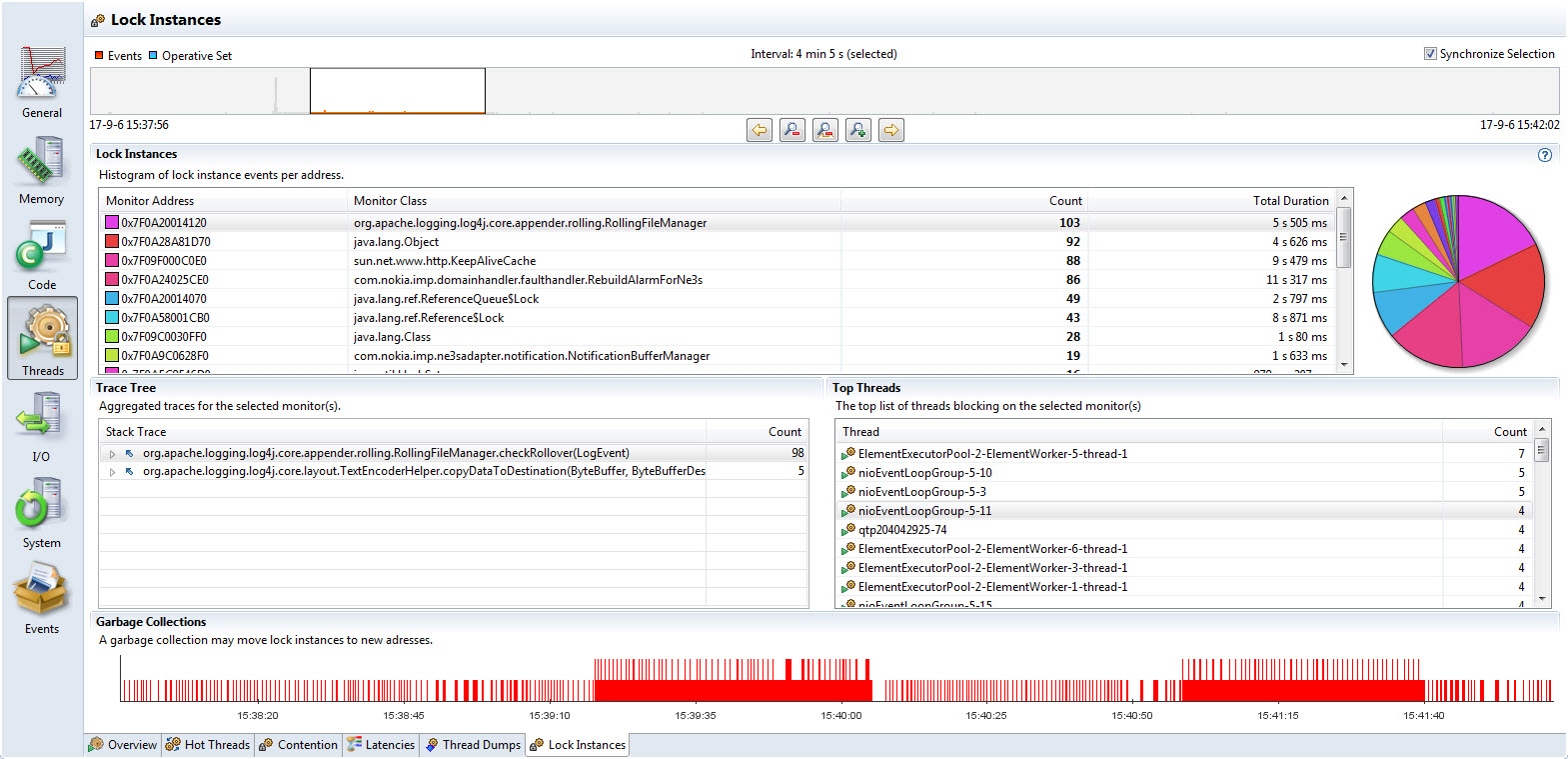
线程锁信息则反馈一些基于Java锁对象为中心的时间信息,对于同一个锁对象指针(底层地址空间的指针)其关联的所有线程的追踪信息,并显示出多个关联线程被采样到的次数信息。
由于这些统计信息是基于操作系统内存地址的,垃圾收集算法可能在运行清理操作的时候拷贝对象从而使得指针被重写,因此该信息不是非常可靠,尤其是GC比较活跃的时候,某些应该被计数在内的线程活动会被计数到不同的实例上。幸运的是,JFR同样对给定的时间段内GC的活动情况给了个概要视图呈现在最下方。
线程Dump情况
JFR会依据采样配置情况,定期保留当前所有线程的调用栈信息;由于堆栈保存对实际运行程序的影响比较大,JFR的默认策略是很长时间才会取样一次调用栈信息。
对于时间比较短的采样,这个页面的信息很可能是空的。如果确定有必要(比如怀疑某些线程僵死的情况,可以通过设置采样参数让JFR提取更多的信息。
IO情况
对于后端应用程序来说,系统性能的提升和IO活动密切相关因为大部分的程序运行瓶颈在IO上, 即快速的CPU处理速度和缓慢的IO活动之间的不可调和的矛盾往往导致应用程序性能的下降;然而大部分的后端应用的目标是追求更高的吞吐率。
当吞吐量上不去,而CPU的运行曲线又不太平稳(譬如有很多锯齿)的情况下,往往是IO的处理浪费了宝贵的运行时间; 此时只要查看IO的情况,减少对程序逻辑的阻塞即可快速提升性能。 如果CPU已经用满,而吞吐率又不太理想,则优化起来就困难重重了;当然这种情况下IO的行为还是值得查看的, 因为不恰当的IO锁或者过多的IO操作仍然可能有潜力去挖掘,只是更加困难一些。
IO事件按照其访问速度的差异一可以大概分为如下几类
- 本地磁盘文件读写操作:其速度和物理磁盘的特性、文件系统以及程序所使用的API、框架等密切相关。典型地如频繁的log操作可能引起额外的小量的IO操作,如果这些操作是阻塞的,则程序的性能会下降比较厉害
- 网络文件系统操作:这类场景往往对应用程序的逻辑是做了隔离的,但是在复杂多变的网络环境下很容易引起性能的急剧恶化;遇到这种情况尽快分析出原因是很关键的。
- 网络通信读写(通过基于TCP/IP的各类协议的程序逻辑信息交换):和网络文件操作类似,不同的是和应用层协议的设计和模式密切相关,对于大的系统而言,定位和分隔问题的边界是必不可少的。
JFR对这些时间都分类列出其操作的时间信息,方便我们进一步定位和分析IO方面的问题。大部分情况下,IO里给出的信息都要结合线程乃至内存的情况综合判断。
系统信息和事件
TBD
Leave a Comment
Your email address will not be published. Required fields are marked *